
NLP 為 Natural Language Processing 的縮寫,中文為自然語言處理。NLP 的目的是為了讓電腦能夠看得懂人類語言的意思。
本篇只是進入 ChatGPT 的基本入門起手式,只講解最皮毛的原理。ChatGPT這個專案,光設備費用就高達好幾十億美金,投入的人力更是不計其數,另還有數不清的模型及演算法,請大家別再天真的以為只憑一已之力就想作出 ChatGPT 這東西。
本篇基本觀念
讀入文章 => 去除停用詞 => 建立 Word2Vec 字典 => 向量化 => 偵測相關詞
向量化
向量化這一詞,英文為 Vector,也是向量的意思。不用緊張 “向量” 是什麼,其實就是把字 “量化” 。比如我們講一件物品,它的重量 “很重”、”正常”、”很輕”,那什麼叫 “正常” 。把重量分成 1kg, 2kg, 3kg…,然後規定 x這個東西必需符合 2kg <= x <= 3kg 才叫正常,這就是量化的過程,所以量化就是數字化。數字化後,才能讓電腦作四則運算。
那麼英文單字這麼多,怎麼量化呢。字元 “A” 量化為 65,字元 “B” 為 66,這就是有名的 ASCII 碼表,是美國人規定的。那麼 “book” 這個單字怎麼量化?
傳統的 NLP 使用如下方式量化。假設只有三個單字,分別為 “book”、”dog”、”pig”,然後使用 one-hot強制規定
book=[1 0 0]
dog=[0 1 0]
pig=[]0 0 1]
也就是使用三個矩陣,每個矩陣三個元素,形成 3*3 的矩陣如下圖
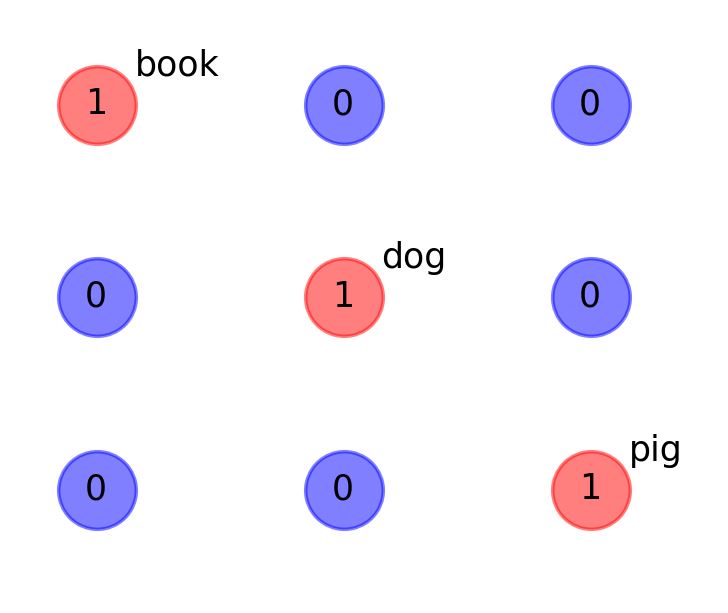
這個方法真的是笨,因為只有對角線有資訊。如果有 1000 個單字,就要有 1000*1000 個空間,然後只有對角線有訊息,其它都是 0,太浪費記憶体了。
Word2Vec
如果能將 “單字” 量化成二維陣列,如下圖所示,那麼就可以省下很多的空間。而且把相近的 (親戚) 集中在一起,虛線可以指向對立 (男女) 的單字,就完美了。
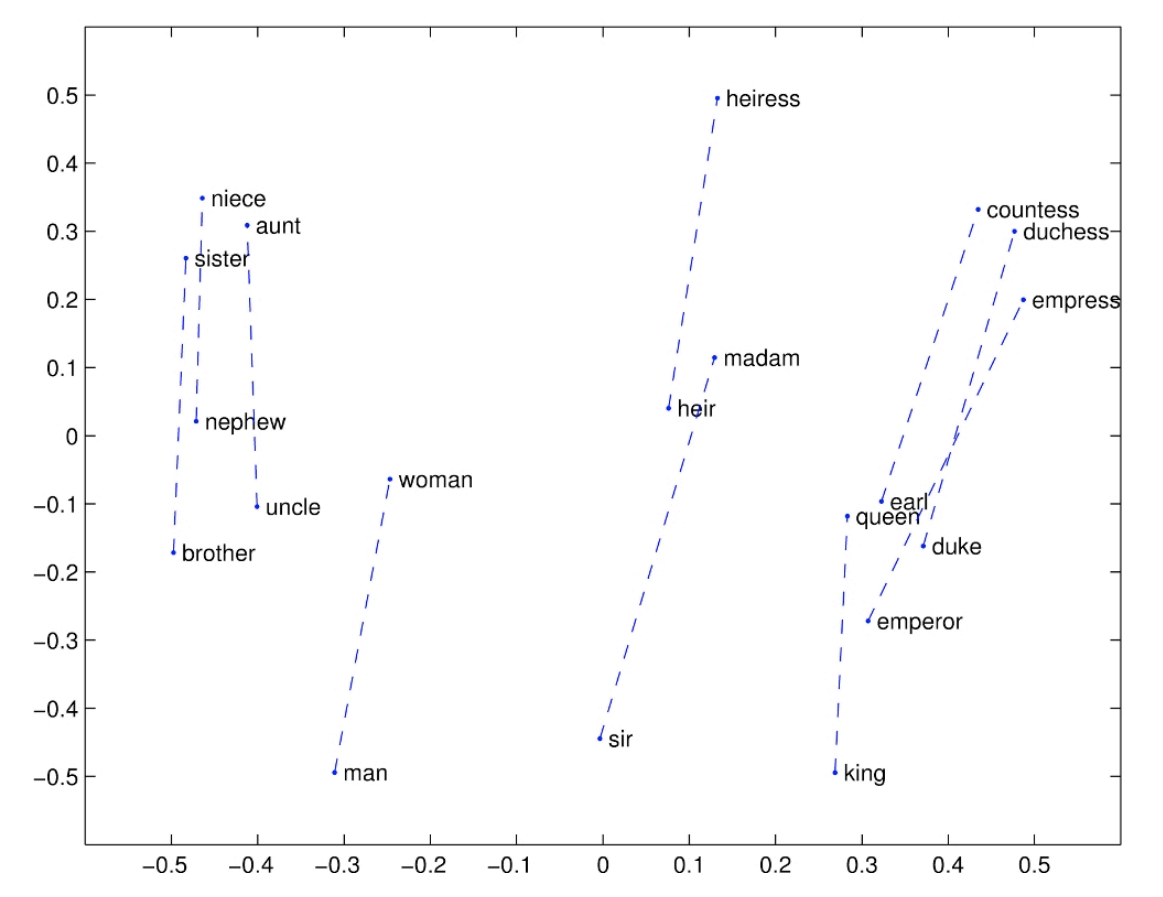
如何產生上面完美的量化結果呢? 2013 年提出聰明的 Word2Vec 模型,使得 NLP 快速發展。而近幾年來有其它的量化方法陸續推出,比如 GloVe, fast Text, ELMo, BERT 等模型。
八字向量化
中國的八字算命,其實就是向量化。八字把每個人的生辰 (年月日時) 分成 4 個特徵,而每個特徵有60種,如下。
時柱 日主 月柱 年柱
戊 庚 庚 癸
寅 子 申 卯
年柱,月柱,日主,時柱,叫作 4 個特徵,每個特徵有60種,所以這世上共有 60*60*60*60 = 12,960,000 (1千2百96萬)種命格。
向量化的結果如下
[戊寅 [43
庚子 30
庚申 39
癸卯 53
] ]
八字就是統計這 1,296 萬個人的命數,幾歲會怎麼樣,某年某月的心情如何,某年某月某日會有啥災難。
這都要耗費百年千年的統計及紀錄,所以八字是吏上最大的工程。
Word2Vec特徵
Word2Vec 將每個字分成 100 個特徵,而每個特徵又有幾種可能呢? 如果以 np.float32來計算,是精準到小數第 7 位,扣除小數點後,就是 6 位數,那麼就是 1,000,000 * 100 = $(10^8)$ = 1 億種可能的語義。
假設共有 10 萬個字,每個字有 100 個特徵,所以有 $(10^8)$ 個特徵,每個特徵又有 100 萬個向量,等於 $(10^{8}*{10}^6=10^{14})$
計算 “A” 這個字的 100 個特徵 – “B” 這個字的 100 個特徵的,平方後的總和,最後再開根號,就是歐幾里得直線距離。