
神經網路(Neural Network)
神經網路至少包含了二個層,即輸入層跟輸出層。
二層感知器
二層感知器中,一個輸入層,另一個為輸出層。比如 28*28的Mnist圖片,展開後就是784個像素。所以輸入層就有784個神經元,輸出層則有10個神經元。如下圖
多層感知器(MLP) Multilayer Perceptron
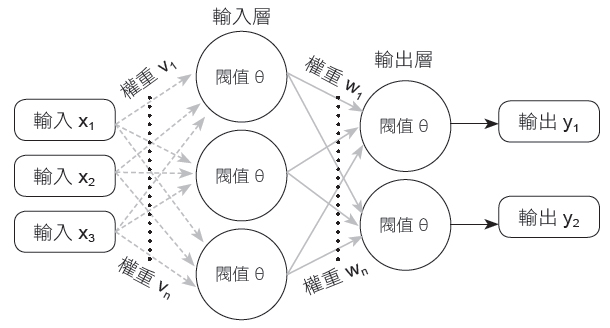
多層感知機是一種前向傳遞類神經網路,在輸入及輸出層外,中間多了至少一個隱藏層。也就是說包含了至少三層結構(輸入層、隱藏層和輸出層),並且利用到倒傳遞技術達到學習(model learning)的監督式學習。如下圖所示。
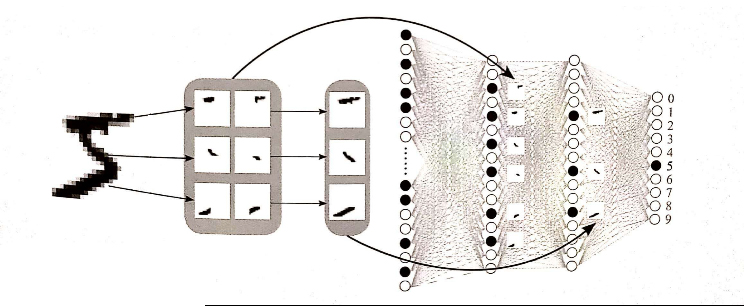
MLP預測手寫數字
底下代碼,實現手寫數字預測,比先前的模型更加準確。
不過在開始預測前,準備好的圖片最好為黑底白字,因為每個字的每個點~~都代表一個 “亮點”,黑色的神經元其值為 0,非黑色的部份其值介>0並且 <=1。然後由這些點計算出迴歸線,所以就有a及b二個參數(y=ax+b)。回歸線就是把二維的資料減少成一條線來表示。
MLP 模型
摸型中先使用Flatten層將28*28二維陣列平化展開成一維具784個元素(特徵點)的陣列。輸出使用softmax()函數,將結果分散在0~9之間10個數字。
訓練時,y_pred=model(train_data_sigmoid),其實就是調用 class Model 的 __call__()方法。那麼我們不就應該覆寫 __call__()嗎,怎麼覆寫 call()?? 因為 __call__()會先作一些事情,然後再調用 call()。所以我們只需覆寫 call() 即可。
請在專案下新增 MLP.py 檔,然後輸入如下代碼。
import tensorflow as tf
import keras
from keras.src.layers import Dense, Flatten
class MLP(keras.Model):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.flatten=Flatten()#將第一維(筆數)以外的維度展平成一維
self.dense1 = Dense(units=500 , activation=tf.nn.relu)#資料由784會變成500個
self.dense2 = Dense(units=400, activation=tf.nn.relu)
self.dense3 = Dense(units=300, activation=tf.nn.relu)
self.dense4 = Dense(units=200, activation=tf.nn.relu)
self.dense5 = Dense(units=100, activation=tf.nn.relu)
self.dense6 = Dense(units=10, activation=tf.nn.softmax)
def call(self, inputs): #[60000,28,28]
x=self.flatten(inputs) #[60000,784]
x = self.dense1(x) #[60000,500]
x = self.dense2(x) # [60000,400]
x = self.dense3(x) # [60000,300]
x = self.dense4(x) # [60000,200]
x = self.dense5(x) # [60000,100]
x = self.dense6(x) # [60000,10]
return x
模型訓練
tf.keras.losses.sparse_categorical_crossentropy稱為交叉熵,可計算其中的值離散程度。值愈大,離散愈大。是以log函數作為統計計算。
模型訓練完整代碼如下。
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
import numpy as np
import keras
from MLP import MLP
learning_rate=0.001
model=MLP()
mnist = tf.keras.datasets.mnist
(train_data, train_label), (test_data, test_label) = mnist.load_data()
optimizer=keras.optimizers.Adam(learning_rate=learning_rate)
#要圖形像素顏色由 0~255 歸一化成 0~1, 否則每次的損失函數值會不一樣
train_data_sigmoid = train_data.astype(np.float32) / 255.0
for i in range(200):#逼近200次, 也就是在訓練模習
with tf.GradientTape() as f:
y_pred=model(train_data_sigmoid)
#crossentropy : 交叉熵
loss=keras.losses.sparse_categorical_crossentropy(y_true=train_label, y_pred=y_pred)
loss=tf.reduce_mean(loss)
print(f"第{i+1:3d}次逼進: loss:{loss.numpy()}")
y_grad=f.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(y_grad, model.variables))
model.save("mlp.keras")
預測
model.predict(new_img) 測出的數字為 n*10的陣列,如[0.01,0.06,0.99,0,0,0,0,0,0,0,0],裏面的數值是每個數的可能機率,所以要找最大值,使用np.argmax(new_pred, axis=-1) 將之轉換成 2。
優化器選用Adam,相關資訊請參考優化器使用
預測完整代碼如下
import numpy as np import tensorflow as tf from keras.src.saving import load_model import pylab as plt from MLP import MLP model=load_model( "mlp.keras", custom_objects={"MLP":MLP} ) mnist=tf.keras.datasets.mnist (train_data, train_labels), (test_data, test_labels) = mnist.load_data() test_data_sigmoid=test_data.astype(np.float32)/255.0 accuracy = tf.keras.metrics.SparseCategoricalAccuracy()#精準度測量器 predict=model.predict(test_data_sigmoid) label=np.argmax(predict, axis=-1)#轉成實際的數字 fig=plt.figure(figsize=(12,6)) for i in range(100): ax=fig.add_subplot(5,20,i+1) ax.imshow(test_data[i], cmap='gray') ax.set_title(label[i]) ax.axis("off") # y_true : 是實際的數字[7 2 1 ...4 5 6] # y_pred : 是預測的機率值 # [ # [0.000e+00 0.000e+00 9.992e-01 8.000e-04 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00 0.000e+00], # [0.000e+00 0.000e+00 0.000e+00 5.000e-04 0.000e+00 9.157e-01 8.380e-02 0.000e+00 0.000e+00 0.000e+00], # ...... # ] accuracy.update_state(y_true=label, y_pred=predict) print(f'精準度 : {accuracy.result()*100:.2f}%') plt.show()

隱藏層
隱藏層愈多愈精準,但會產生過渡擬合,所以需要加池化層。
Model 隱藏層愈多,GPU的效能就會突顯出來,所以GPU所耗資源就會變高。
相對的,如果 epoch 愈多,因為是使用 Python 的迴圈運作,那麼使用 CPU 的效能會高一點,當然CPU所耗資源也更高。
自定義層 — todo
如果要自定義層,可以繼承tf.keras.layers.Layer,然後覆寫 __init__, build及call三個方法,整個架構如下
import tensorflow as tf
class LinearLayer(tf.keras.layer.Layer):
def __init__(self, units):
super().__init__()
self.units=units
def build(self, input_shape):
self.w = self.add_variable(name='w',shape=[input_shape[-1], self.units], initializer=tf.zeros_initializer())
self.b = self.add_variable(name='b',shape=[self.units], initializer=tf.zeros_initializer())
def call(self, inputs):
y_pred = tf.matmul(inputs, self.w) + self.b
return y_pred
class LinearModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.layer = LinearLayer(units=1)
def call(self, inputs):
output = self.layer(inputs)
return output
參數調整
常聽人說,模型有許多參數要調整。當我們自已建立模型,要改的東西就變的很有彈性,比如
1. 演算層,加入池化層
2. 損失函數 (Adam/SGD…)
3. learning_rate
4. epoch