
生成式對抗網路 (Generative Adversarial Network),簡稱GAN。
generative [ˋdʒɛnə͵rətɪv] 生殖的;有生產力的
Adversarial [͵ædvɚˋsɛrɪəl] 敵手的;對手的;對抗的
近來超級火紅的Generative Adversarial Network 中文翻譯為生成式對抗網路。這種演算法被自稱是 AI 大師的人解釋成好像可以產生出更新、更高解析、更高科技的最佳發明,簡直是可以無中生有 (Create something from nothing) 的尖端科技。但事實是殘酷的,由真實的事件(比如真實的照片)產生出人類無法辨識的假照片,這些照片都是假的。
生成對抗網路由一個生成網路與一個判別網路組成,通過兩個神經網路相互博弈的方式進行學習。該方法由 Ian(伊恩·古德費洛) 等人於2014年提出。生成網路從潛在空間(latent space)中隨機取樣作為輸入,其輸出結果需要盡量模仿訓練集中的真實樣本。判別網路的輸入則為真實樣本或生成網路的輸出,其目的是將生成網路的輸出從真實樣本中盡可能分辨出來。而生成網路則要盡可能地欺騙判別網路。兩個網路相互對抗、不斷調整參數,最終目的是使判別網路無法判斷生成網路的輸出結果是否真實。
生成對抗網路常用於生成以假亂真的圖片。此外,該方法還被用於生成影片、三維物體模型等。生成對抗網路雖然最開始提出是為了無監督學習,但經證明對半監督學習、完全監督學習 、強化學習也有效。 在2016年的一個研討會上,生成式對抗網路被譽為機器學習這二十年來最酷的想法。
監督式學習
在 Yolov8 的說明中,必需標示圖片中的物件是人類,腳踏車,杯子,餐桌…… 共80種。而每一種又有上千張圖片,這些全都需要人工標識並告知是那一個種類,最後才丟進模型進行訓練,這叫監督式學習。
標識圖片的工作,通常是由美工人員負責,所以一般公司都要聘請多位美工人員標識每天上千到上萬張的圖片。
非監督式學習
美工人員每天重複無腦的動作,一天上萬張圖不斷的標識,薪水低又每天加班。Gan 就是讓這些美工人員失業的最佳方案,因為它可以應用在非監督式學習,電腦自已標識圖片,然後自已訓練。
電腦不斷學習的結果
Gan 的真正作用,是要用在非監督式學習,並不是讓電腦不斷的學習,怎麼說呢?
讓 A 模型學習 B 模型的真實的事情,進而產生新的東西。然後新的東西再學習新的東西,一直不斷的學習,不就達成魔鬼終者的世界嗎! 那為啥不直接說會進入神的領域! 一台破電腦直接變成神?
不要忘了一件事,A 模型學習 B 模型真實的事件,產生出的新東西是假的。假的東西再學習假的,只會愈學愈假,最後就是四不像。
DCGAN
生成式對抗網路是無中生有的東西,DCGAN(Deep Convolutional GAN)是 GAN 的經典改良版,由 Alec Radford 等人在 2015 年提出。速度比 GAM 更快且像片品質更佳。
網路上的教學,都說 GAN 可以把模糊圖片變成高清晰、2D 可以變成 3D,是沒錯,因為連專家也判斷不出真假。但真的要產生 1024*768 的圖片,不是一般顯卡作的出來的。所以圖片大小僅限於100~200相素左右。
本篇使用 Mnist 的 60000 張真圖進行訓練。
模型組合
一開始若不把下面的模型組合搞清楚,程式碼就會看不懂。
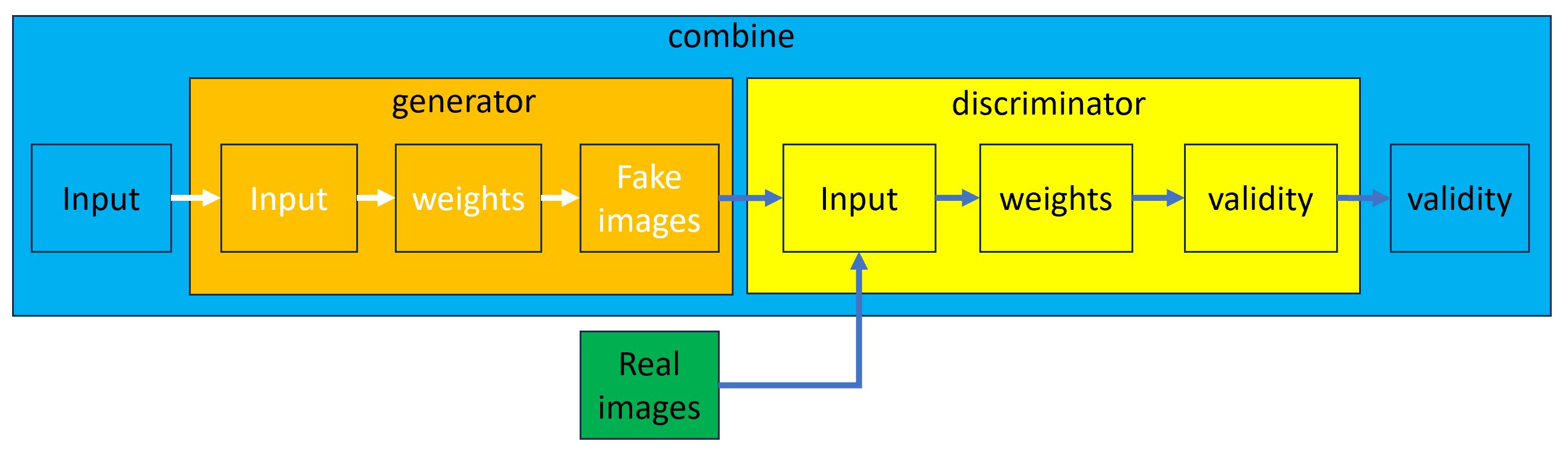
首先產生 generator 模型,此模型輸入雜訊,經過權重計算,由 generator(noise) 產生 Fake images。
接下來建立 discriminator 鑑識模型,此模型的 Input 輸入資料就是 generator 的 Fake images ,再使用 discriminator.train_on_batch() 產生黃色端的 validity 資料。
請注意 discriminator.trainable = True,訓練時黃色的權重會被調整而提高辨識能力。但本程式沒有辨識的功能,而是直接告知這是真圖或是假圖,所以把 trainable 設為 False,以提高訓練效能。
combine 是 generator 及 discriminator 的結合體。此模型的 Input 會傳給 generator 的 Input,輸出 Fake images 後傳給 discriminator 的 Input, discriminator 的 validity 最後再傳給 combine 的 validity 。
那麼 generator 裏的權重要如何訓練呢? 就是由 combine.train_on_batch() 啟動訓練,讓 generator 產生的圖像愈來愈接近真實的狀況。
安裝套件
底下使用 pytorch,請先安裝如下套件
pip install matplotlib pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130 --no-cache-dir
觀念
使用 Mnist 的手寫資料進行訓練,然後由這些資料無中生出其它的圖片。本例的模型訓練需一點時間,無法訓練的人,請由如下網址下載。
載入圖片資料
pytorch 也有 Mnist 的手寫資料,請由如下代碼測試
from torchvision import datasets, transforms
import pylab as plt
dataset = datasets.MNIST(
root="./data",
train=True,
download=True,
#transform=transforms.ToTensor()
)
for i in range(50):
img, label=dataset[i]
plt.subplot(5,10,i+1)
plt.axis('off')
plt.imshow(img, cmap='gray')
plt.title(label)
plt.show()
train = True 時,會有60000張圖片,train=False 時,只有 10000張。第一次執行時,download 必需是 True。若第一次沒資料而 download 為 False,則會報錯。
dataset 是圖型及 Label 的資料,此處只要顯示圖片,所以不需要 transform。若要進行模型訓練,需使用 transforms.ToSensor 轉換成 pytorch 格式。

Generator 模型
新增 Generator.py,內容如下
import torch.nn as nn
# Generator 模型
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
# input (100,1,1)
nn.ConvTranspose2d(
#LATENT_DIM,
100,
256,
kernel_size=7,
stride=1,
padding=0,
bias=False
),
nn.BatchNorm2d(256),
nn.ReLU(True),
# (256,7,7)
nn.ConvTranspose2d(
256,
128,
kernel_size=4,
stride=2,
padding=1,
bias=False
),
nn.BatchNorm2d(128),
nn.ReLU(True),
# (128,14,14)
nn.ConvTranspose2d(
128,
1,
kernel_size=4,
stride=2,
padding=1,
bias=False
),
# (1,28,28)
#雙曲正切函數(Hyperbolic Tangent),是一種激活函數(activation function)
#會把輸入壓縮到 -1 ~ 1 之間
#tanh(x) = (e ^ x - e ^ -x) / (e ^ x + e ^ -x)
nn.Tanh()
)
def forward(self, z):
return self.model(z)
Discriminator 模型
Discriminator 模型是判別器,完整代碼如下。
import torch.nn as nn
# Discriminator 模型
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
# (1,28,28)
nn.Conv2d(
1,
64,
kernel_size=4,
stride=2,
padding=1
),
nn.LeakyReLU(0.2, inplace=True),
# (64,14,14)
nn.Conv2d(
64,
128,
kernel_size=4,
stride=2,
padding=1
),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# (128,7,7)
nn.Flatten(),
nn.Linear(
128 * 7 * 7,
1
),
nn.Sigmoid()
)
def forward(self, img):
return self.model(img)
模型訓練
底下是訓練模型的完整代碼
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from Discriminator import Discriminator
from Generator import Generator
# 參數設定
BATCH_SIZE = 128
#BATCH_SIZE = 500
LATENT_DIM = 100#每張圖片由 100 個隨機數描述。
EPOCHS = 50
LR = 0.0002
device = torch.device(
"cuda" if torch.cuda.is_available()
else "cpu"
)
print("Device =", device)
# 權重初始化
def weights_init(m):
classname = m.__class__.__name__
if "Conv" in classname:#捲積層
nn.init.normal_(
m.weight.data,
0.0,
0.02
)
elif "BatchNorm" in classname:#批次正規化
nn.init.normal_(
m.weight.data,
1.0,
0.02
)
nn.init.constant_(
m.bias.data,
0
)
# 載入 MNIST
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
[0.5],
[0.5]
)
])
dataset = datasets.MNIST(
root="./data",
train=True,
download=True,
transform=transform
)
dataloader = DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
# 建立模型
generator = Generator().to(device)
discriminator = Discriminator().to(device)
generator.apply(weights_init)
discriminator.apply(weights_init)
# Optimizer
optimizer_G = optim.Adam(
generator.parameters(),
lr=LR,
betas=(0.5, 0.999)
)
optimizer_D = optim.Adam(
discriminator.parameters(),
lr=LR,
betas=(0.5, 0.999)
)
# 開始訓練
for epoch in range(EPOCHS):
for i, (real_imgs, _) in enumerate(dataloader):
real_imgs = real_imgs.to(device)
batch_size = real_imgs.size(0)
valid = torch.ones(
[batch_size,1],
device=device
)
fake = torch.zeros(
[batch_size,1],
device=device
)
# Train Discriminator
optimizer_D.zero_grad()
real_loss = nn.BCELoss()(
discriminator(real_imgs),
valid
)
#產生假圖
z = torch.randn(
[batch_size,LATENT_DIM,1,1],
device=device
)
fake_imgs = generator(z)
fake_loss = nn.BCELoss()(
discriminator(fake_imgs.detach()),
fake
)
#判別器的損失函數,GAN論文寫出由 (real_loss+fake_loss)/2
d_loss = (real_loss +fake_loss)/2
d_loss.backward()
optimizer_D.step()
# Train Generator
optimizer_G.zero_grad()
z = torch.randn(
[batch_size,LATENT_DIM,1,1],
device=device
)
gen_imgs = generator(z)
#判斷假圖有沒有成功騙過判別器
g_loss = nn.BCELoss()(
discriminator(gen_imgs),
valid
)
g_loss.backward()
optimizer_G.step()
print(
f"Epoch [{epoch+1}/{EPOCHS}] "
f"Batch [{i}/{len(dataloader)}] "
f"D Loss={d_loss.item():.4f} "
f"G Loss={g_loss.item():.4f}"
)
#sample_images(epoch + 1)
#generator.train()
# 儲存模型
torch.save(
generator.state_dict(),
f"generator_{EPOCHS}.pth"
)
torch.save(
discriminator.state_dict(),
f"discriminator_{EPOCHS}.pth"
)
print("Training Finished")
產生假圖
底下是產生假圖的完整代碼
import torch
import matplotlib.pyplot as plt
from Generator import Generator
EPOCHS = 50
generator = Generator()
generator.load_state_dict(
torch.load(f"generator_{EPOCHS}.pth")
)
#從訓練模式切換到推論模式
#generator.eval()
#with torch.no_grad():
z = torch.randn(
25,#產生 25 張圖
100,#每張圖由 100 隨機數描述
1,
1
)
imgs = generator(z).detach() #會先執行 __call__(z)初始化一些設定,然後執行 generator.forward()
imgs = (imgs + 1) / 2
fig, axs = plt.subplots(5,5)
for i in range(5):
for j in range(5):
axs[i][j].imshow(imgs[i*5+j][0],cmap="gray")
axs[i][j].axis("off")
plt.show()

Tensorflow 版
安裝套件
請先安裝如下套件
pip install tensorflow==2.10.1 matplotlib
程式運作流程
主程式中產生 gan=Gan() 物件。這個物件建構子會產生二個模型
generator 模型
此模型 input 層接收隨機產生的 100 個雜訊,用這個雜訊產生 256 => 512 => 1024 個資料,最後產生 784 個點形成圖片。
def build_generator(self):
model = Sequential()
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
input = Input(shape=(self.latent_dim,))
img = model(input)
return Model(input, img)
Discriminator [dɪˋskrɪmə͵netɚ] 模型 (鑑識器)
用來判斷產生的圖片與原圖的相似度,輸入層是 784 個相素的圖片,最後縮小成 512 => 256 => 1 個資料
def build_discriminator(self):
model = Sequential()
model.add(Flatten(input_shape=self.img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
input = Input(shape=self.img_shape)
validity = model(input)
return Model(input, validity)
combine
combine 由 generator 及 discriminator 二個模型組合成成
self.combine= Model(input, self.discriminator(self.generator(input))
請注意,要訓練 generator 的權重,不是由 generator.train() 訓練,而是由 combine.train_on_batch() 開始訓練。
train
最後再由主程式啟動 train 開始訓練。
模型下載
底下的完整代碼,訓練需要一段時間,沒顯卡會非常的久。所以無法訓練的人,請由本站下載 gan_mnist。本模型是本人訓練 10 萬次的結果。
完整代碼
本篇的完整代碼是參考 https://github.com/eriklindernoren/Keras-GAN/blob/master/gan/gan.py 修改而來的。
修改的部份為
1. 將模型獨立成一個類別
2. 訓練的指令放在主程式中
3. 一次讀入10000張圖片訓練
完整代碼如下
import os.path
import shutil
import numpy as np
from keras import Sequential, Input, Model
from keras.datasets import mnist
from keras.layers import Dense, LeakyReLU, BatchNormalization, Flatten, Reshape
from keras.optimizers import Adam
import pylab as plt
class Gan():
def __init__(self):
self.img_rows = 28#寬
self.img_cols = 28#高
self.channels = 1 #單色
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100#等會產生100個雜點
optimizer = Adam(0.0002, 0.5)
# 建立 discriminator 模型
self.discriminator=self.build_discriminator()
self.discriminator.compile(
loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy']
)
# 建立 generator 模型
self.generator=self.build_generator()
input=Input(shape=(self.latent_dim))
img=self.generator(input)#產生輸出層,不是真正的圖
# discriminator 不訓練權重,因為本例不進行辨識
#而是真接告知圖片的真假
self.discriminator.trainable=False
#self.discriminator.trainable = True
output=self.discriminator(img)#產生輸出層,不是結果
self.combin= Model(input, output)
self.combin.compile(
loss="binary_crossentropy",
optimizer=optimizer
)
def build_generator(self):
model=Sequential()
model.add(Dense(256, input_dim=self.latent_dim))
#relu : 線性整流,將負值去除。LeakyReLU剛好相反,將值變成有負值
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
#np.prod([1,2,3]) = 1*2*3 = 6
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
input=Input(shape=(self.latent_dim))
output=model(input)#輸入input層,產生 output層
return Model(input, output)
def build_discriminator(self):
model = Sequential()
#在第一層中,如果指定 input_shape, 則會在第一層前產生輸入層
model.add(Flatten(input_shape=self.img_shape))#產生了二層
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
#sigmoid, 結果為 0 or 1,用於二分法
model.add(Dense(1, activation="sigmoid"))
input=Input(shape=self.img_shape)#產生輸入層
model.summary()
output=model(input)#產生輸出層
return Model(input, output)
def sample_images(epoch):
r, c = 5, 5
noise = np.random.normal(0,1,(r * c, latent_dim))
gen_imgs = gan.generator.predict(noise)#也可以直接寫成 self.generator(noise)
#將顏色值還原成 0-255之間
gen_imgs = (0.5 * gen_imgs +0.5)*255
fig,axs=plt.subplots(r,c)
idx=0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[idx, :,:,0], cmap="gray")
axs[i,j].axis("off")
idx+=1
fig.savefig(f"images/{epoch}.png")
plt.close()
#設定圖檔儲存路徑
path="./images"
if os.path.exists(path):
shutil.rmtree(path)
os.mkdir(path)
batch_size=10000#每次讀入的圖片張數
epochs=10000#訓練的次數
latent_dim=100#潛在空間的雜訊數量
sample_interval=100 #設定多少 epoch 才儲存一次圖檔
#載入60000張圖片
(x_train, _), (_,_)=mnist.load_data()
#產生模型
gan=Gan()
#假圖標識為0, 真圖標識為 1
fake = np.zeros((batch_size, 1))
valid = np.ones((batch_size, 1))
#將顏色置於 -1 ~ 1 之間
x_train = x_train /127.5 -1.
x_train = np.expand_dims(x_train, axis=3)
for epoch in range(epochs):
#取出 batch_size 個數字,每個數字介於 0~59999之間
idx=np.random.randint(0, x_train.shape[0], batch_size)
real_imgs = x_train[idx]
#產生 batch_size 組亂數, 每組有 100 個數
noise=np.random.normal(0,1,(batch_size, latent_dim))
#產生假的圖片,不是產生層
fake_imgs=gan.generator(noise)
#開始訓練 model.fit(x, y)
#底下會自動調整 discriminator 的權重
d_loss_real = gan.discriminator.train_on_batch(real_imgs, valid)
d_loss_fake = gan.discriminator.train_on_batch(fake_imgs, fake)
#底下只是為了顯示而以
d_loss = np.add(d_loss_real, d_loss_fake)/2.0
#訓練 generator
#由 combin 去啟動 generator 的訓練,然後調整 generator 的權重
g_loss = gan.combin.train_on_batch(noise, valid)
print(f"Epoch:{epoch:06d} D loss:{d_loss[0]:.6f}, acc:{100*d_loss[1]:.6f}%, G loss:{g_loss:.6f}")
if epoch % sample_interval == 0:
sample_images(epoch)
#最後將 generator 的權重儲存
gan.generator.save("gan_mnist")
結果
一開始產生的照片如下

最後一次產生的照片如下

這種無中生有的東西竟然會發生在這世界上,人類想當上帝真的是想瘋了。
載入 generator 模型直接產生新圖
前面的代碼中,我們將 generator 的權重儲存在 gan_mnist 目錄中。所以下次不想重新訓練,而是想直接產生新圖時,就可以使用如下代碼
from keras import models import numpy as np import pylab as plt generator=models.load_model("gan_mnist") r, c = 5, 5 np.random.seed(10) noise = np.random.normal(0, 1, (r * c, 100)) gen_imgs = generator.predict(noise) # 也可以直接寫成 self.generator(noise) # 將值改為 0-1之間 gen_imgs = (0.5 * gen_imgs + 0.5)*255 fig, axs = plt.subplots(r, c) idx = 0 for i in range(r): for j in range(c): axs[i, j].imshow(gen_imgs[idx, :, :, 0], cmap="gray") axs[i, j].axis("off") idx += 1 plt.show()