
OCR引擎(Optical Character Recognition 光學字元辨識)
tesseract[`tesərækt](四度空間)為HP實驗室於1985年開始研發,至1995年時已經成為OCR業內最準確的三款識別引擎之一。HP後來放棄OCR業務,Tesseract停止研發。數年後,HP將Tesseract貢獻給開源軟件業.。2005年 Tesseract由美國內華達州信息技術研究所獲得,並求諸於Google對Tesseract進行改進、消除Bug、優化工作。
Tesseract可以指定下載要辨識的語言,所以屬於離線作業,辨識時並不需網路取得文字資料。
安裝引擎
Windows環境
在Windows下,tesseract引擎可由如下網址下載
https://digi.bib.uni-mannheim.de/tesseract/
請選取最新且非dev,非alpha的版本。目前最新版本為 tesseract-ocr-w64-setup-v5.0.1.20220107.exe 。安裝時, 請選取 Additional language data(download),然後勾選要支援的語言。
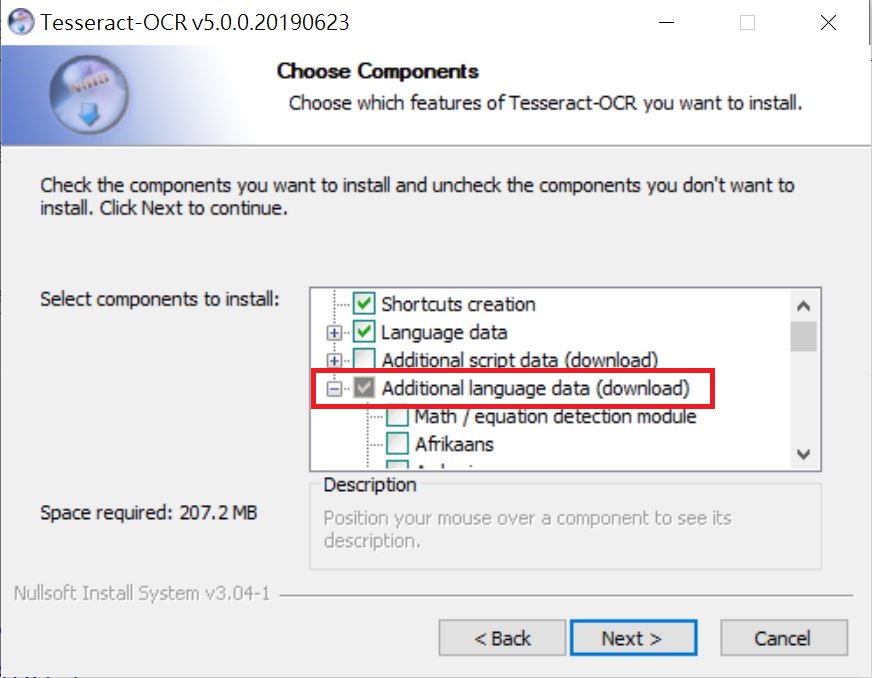
最後請將 “C:\Program Files\Tesseract-OCR” 加到系統變數Path中。
請注意,Path設定好後,Pycharm必需關閉重新啟動,上面的Path才會重新生效。
另外請注意,安裝Additional language data時會出現錯誤,無法安裝,請依下述方式手動新增訓練資料
Linux環境
在ubuntu裏要安裝OCR引擎,只需如下指令即可
sudo apt-get tesseract-ocr
安裝中文字型訓練資料
上述安裝tesseract引擎時,選取Additional language data時,會出現錯誤。請到 https://github.com/tesseract-ocr/tessdata 選取chi_tra.traineddata ,然後按下Download
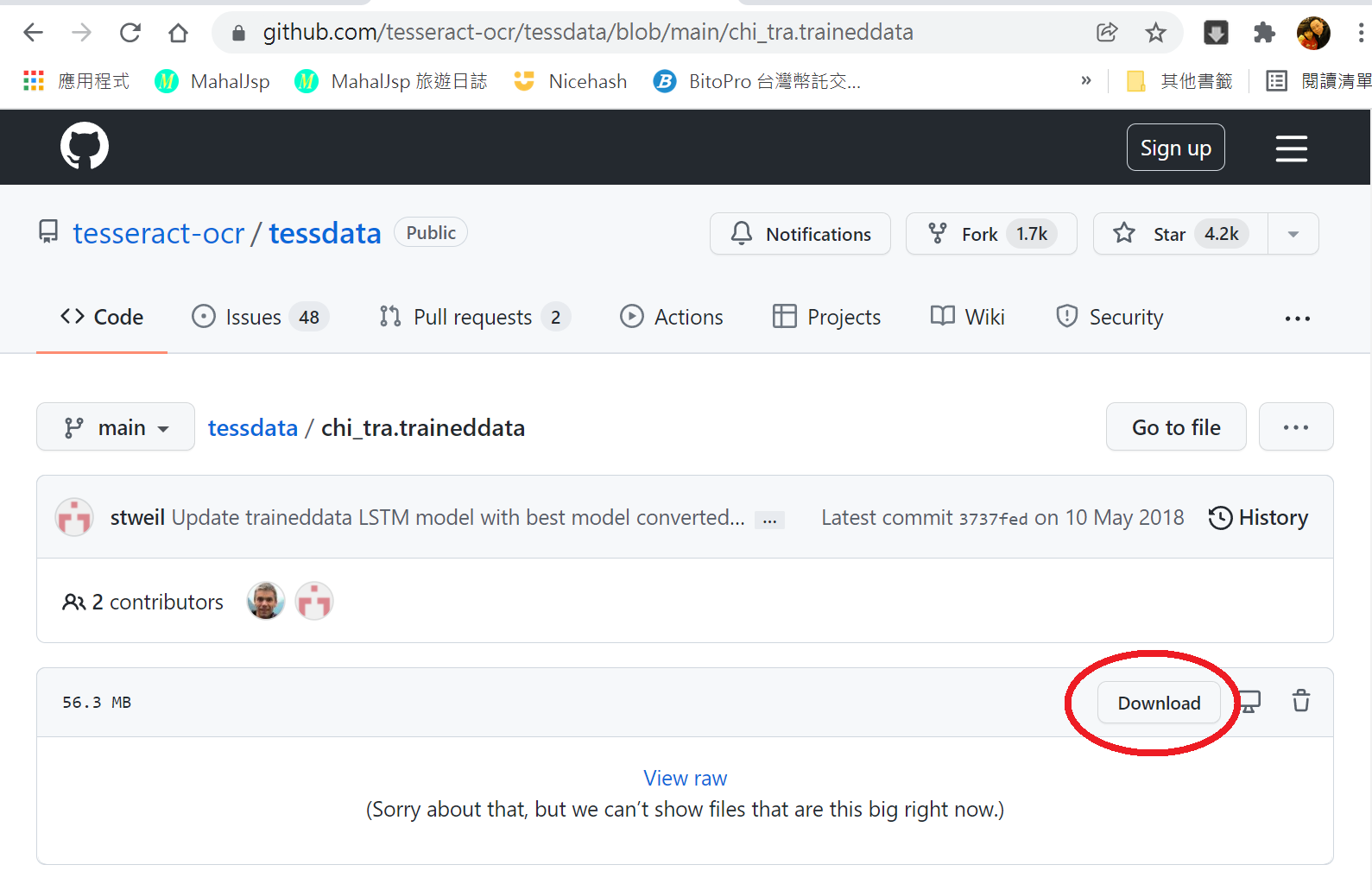
然後把 chi_tra.traineddata copy 到 C:\Program Files\Tesseract-OCR\tessdata 目錄之下即可
Python套件安裝
pip install pytesseract, pillow
pytesseract只是一個使用Python包裝起來的套件,它只負責將圖片傳給OCR引擎,然後接收OCR引擎轉換後傳出的文字而以。而Pillow是Image圖形處理套件。
pytesseract.image_to_string(image, lang=’chi_tra’)
首先使用urllib自網路上下載圖片。urllib是系統就安裝好的套件,無需另行下載。置入tesseract的影像image必需為OpenCv的影像格式,且轉成灰階256後的效果更為精準。
import pytesseract
import requests
import cv2
import numpy as np
import pylab as plt
url="http://mahaljsp.asuscomm.com/wp-content/uploads/2020/12/scikt_data.jpg"
response = requests.get(url)
img = cv2.imdecode(np.array(bytearray(response.content), dtype=np.uint8), cv2.IMREAD_GRAYSCALE)
#字体盡可能放大,字愈大辨識率愈好
#有時二值化造成字体模糊,辨識率會降低
#lang="chi_tra" 為繁体中文
#ret, img =cv2.threshold(img, 180,255, cv2.THRESH_BINARY)
result=pytesseract.image_to_string(img,lang='eng')
print("result:",result)
plt.imshow(img, cmap="gray")
plt.show()
結果 :
Load_digits skLearn.datasets._base
load_boston skLearn.datasets._base
load_diabetes skLearn.datasets._base
load_fiues skLearn.datasets._base
load_inris skLearn.datasets._base
load_breast_cancer skLearn.datasets._base
load_linnerud skLearn.datasets._base
load_sample_image(image_name) skLearn.datasets._base
load_sample_images() skLearn.datasets._base
1oad_svmlight_file skLearn.datasets._svmLight_format_io
Load_svmuight_fiLes “skLearn.datasets._svmLight_format_10
skLearn.datasets._base
Load_wine
lang為指令要辨識的語言,如下所示
chi_sim : 簡体中文 chi_tra : 繁体中文 eng : 英文 fra : 法文
準確度
tesserocr僅能解決實心的圖形文字, 對於空心的文字依然無法辨識. 畢竟電腦不是人腦, 只能使用深度學習訓練機器識別
簡繁轉換
下載套件
langconv.py : /files/langconv.py
zh_wiki.py : /files/zh_wiki.py
作法
from langconv import Coverter
str_sp='测试'
str_td=Converter('zh-hant').convert(str_sp)
print('簡轉繁'+str_td)
str_td="測試"
str_sp=Converter('zh-hans').convert(str_td)
print('簡轉繁'+str_sp)
todo
https://www.itread01.com/articles/1476089156.html