
Support Vector Machines, SVM
SVM是一種非常經典的資料分類演算法,稱為支持向量機。其目的是在找出一個超平面,將二個不同的集合分開。
所謂的超平面,其實是指高維度而以。比如在二維中,找到一條線將二者分開,這一條線就是超平面。若在三維空間中,找到一個平面將二者分開,那麼這一個平面也叫超平面。同樣的,四維中找到三維,那麼三維也叫超平面。
SVM分為線性可分集合及非線性可分集合。
線性可分集合
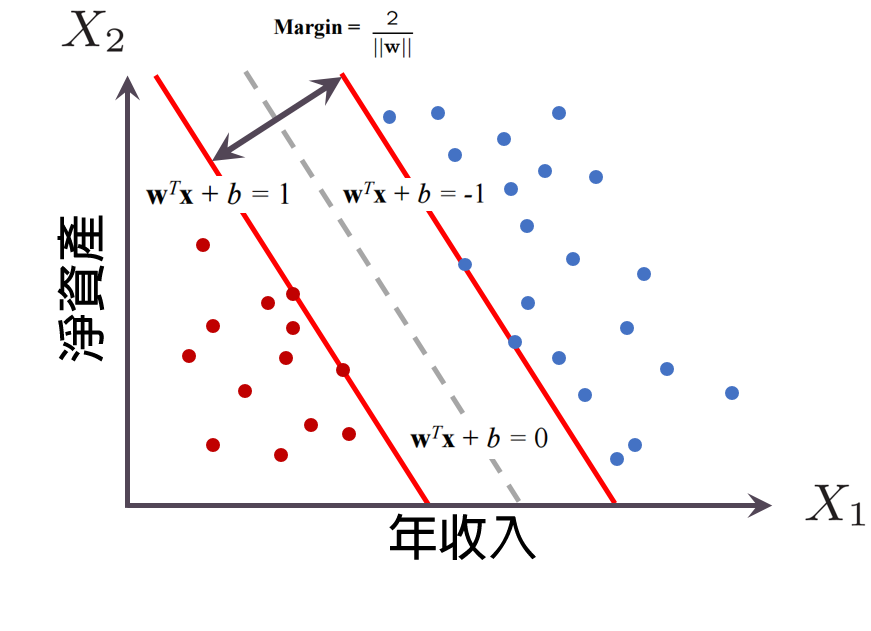
如下圖,資料可分為左右二邊的二種狀況。以信用卡客戶為例,紅點為不按時繳錢的客戶,藍點為信用良好的客戶。
為什麼客戶會違約呢?? 銀行當然會對客戶的一些條件進行分析。比如客戶的總資產,薪資,負債,貸款,是否有賭博習慣,是否為澳客習慣性積欠等因素進行評估。但條件愈多愈難評估,也愈難講解,所以此例僅就總資產及薪資二個條件評估。
下圖的每個點都是給定的訓練實例,每個訓練實例被標記為屬於兩個類別中的其中一個。SVM訓練演算法會將一個新的實例分配給兩個類別其中之一,使其成為非概率的二元線性分類器。
SVM模型將實例表示為空間中的點,這樣對應就使得單獨類別的實例被盡可能寬度間隔分開。然後將新的實例對映到同一空間,並基於它們落在間隔的哪一側來預測所屬類別。所以SVM簡單的說,就是計算中間灰色虛線的演算法。
非線性可分集合
如果不是一條線可以分開的話呢。以下圖而言,紅藍可能質量不一樣,所以就可以往桌子上一拍,讓質量較輕的紅點行上跳高一點,較重的藍點會跳低一點,所以就可以在中間產生一個超平面,將二者分開。這就是SVM使用核函數技巧,有效地進行非線性分類,將其輸入隱式對應到高維特徵空間中。
當資料未被標記時,不能進行監督式學習,需要用非監督式學習,它會嘗試找出資料到叢集的自然聚類,並將新資料對映到這些已形成的叢集中。

手寫數字實例練訓
底下使用SVM模型來預測手寫的數字。首先由svm.SVC產生model模型,再用model.fit()開始訓練模型。傳入模型的資料必需是二維陣列,第 0 維為訓練的筆數,第 1 維為每筆資料的長度。所以如果是1000張圖片的話,必需把這1000張的長寬轉成 (1000, w*h)。
第1維的資料長度,可以想像成不同的狀況。比如要預測房價的漲或跌,可把影響房價的因素列出,比如通膨狀況,有無戰爭,有無疫情,物價指數,人口數,死亡數,地點等等因素。反正就是因素愈多就愈準確。
最後使用model.predict()將要預測的資料傳入,即可取得計算後的結果。
svm.SVC(C=100., kernel=’linear’),C為懲罰係數,數字愈大,愈不能容忍誤差,當然也會降低速度。
執行代碼之後,這下神奇了,幾乎全部都正確了
from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.preprocessing import scale import pylab as plt from sklearn import svm #載入資料並進行標準常態分配 digits = datasets.load_digits() data = scale(digits.data) #拆開資料,3/4為訓練資料,1/4為預測資料 x_train, x_test, y_train, y_test = train_test_split(data, digits.target, train_size=0.75, random_state=42) #建立模型 model = svm.SVC(C=100., kernel='linear') #開始訓練模型 model.fit(x_train, y_train) #傳入預測資料並取得結果 predict = model.predict(x_test) for i in range(50): sub=plt.subplot(5,10,i+1) sub.set_title(predict[i]) sub.set_xticks([]) sub.set_yticks([]) sub.imshow(x_test[i].reshape(8,8), cmap='gray') plt.show()

使用 mnist 資料
底下使用 mnist 的資料進行訓練偵測,但使用 svm.SVC訓練60000筆資料要非常久,所以可以改用
model = svm.LinearSVC(C=100.)。LinearSVC也是線性演算法,但跟SVC不一樣,速度較快。使用 mnist 時,請先執行如下指令安裝 tensorflow
pip install tensorflow
完整代碼如下
#from keras.datasets import mnist import tensorflow as tf import pylab as plt from sklearn import svm mnist=tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test)=mnist.load_data() x_train=x_train.reshape(60000,784) x_train=x_train[:10000] y_train=y_train[:10000] x_test=x_test.reshape(10000,784) x_test=x_test[:100] y_test=y_test[:100] #建立模型 model = svm.SVC(C=100., kernel='linear')
#LinearSVC為線性演算,但演算法跟 SVC不一樣,速度較快,可用來訓練60000筆資料
#model = svm.LinearSVC(C=100.) #開始訓練模型 model.fit(x_train, y_train) #儲存模型可以使用底下的二種方法 #joblib.dump(model, "mnist_model") pickle.dump(model, open("model.pkl", "wb"), protocol=0) #傳入預測資料並取得結果 predict = model.predict(x_test) for i in range(50): sub=plt.subplot(5,10,i+1) sub.set_title(predict[i]) sub.set_xticks([]) sub.set_yticks([]) sub.imshow(x_test[i].reshape(28,28), cmap='gray') plt.show()

載入模型
載入模型也可以使用底下二種方式
import pickle
import joblib
from keras.datasets import mnist
import pylab as plt
#model=joblib.load("mnist_model")
with open("model.pkl",'rb') as f:
model=pickle.load(f)
(x_train, y_train), (x_test, y_test)=mnist.load_data()
x_test=x_test[:100]
x_test=x_test.reshape((100,784))
labels=model.predict(x_test)
for i in range(50):
ax=plt.subplot(5,10,i+1)
ax.axis("off")
ax.set_title(labels[i])
ax.imshow(x_test[i].reshape((28,28)), cmap='gray')
plt.show()