
MLP多層感知器
神經網路(Neural Network)
神經網路至少包含了二個層,即輸入層跟輸出層。
二層感知器
二層感知器中,一個輸入層,另一個為輸出層。比如 28*28的Mnist圖片,展開後就是784個像素。所以輸入層就有784個神經元,輸出層則有10個神經元。如下圖
多層感知器(MLP) Multilayer Perceptron
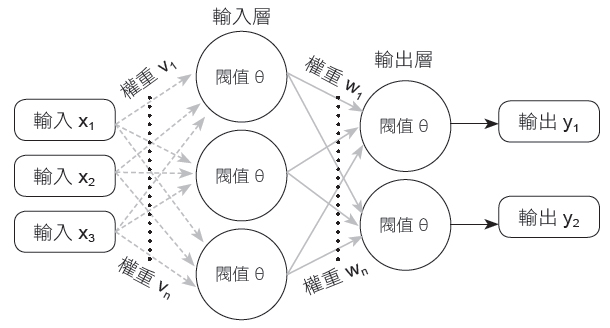
多層感知機是一種前向傳遞類神經網路,在輸入及輸出層外,中間多了至少一個隱藏層。也就是說包含了至少三層結構(輸入層、隱藏層和輸出層),並且利用到倒傳遞技術達到學習(model learning)的監督式學習。如下圖所示。
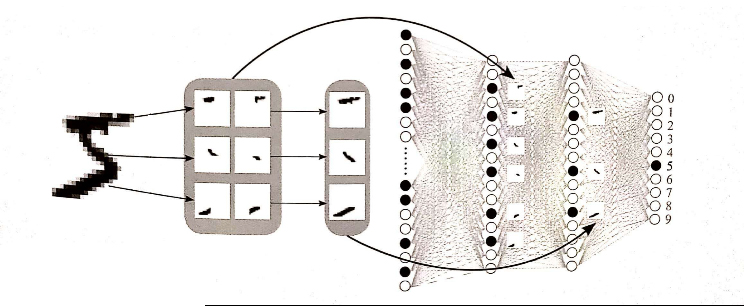
MLP預測手寫數字
底下代碼,實現手寫數字預測,比先前的模型更加準確。
不過在開始預測前,準備好的圖片最好為黑底白字,因為每個字的每個點~~都代表一個 “亮點”,黑色的神經元其值為 0,非黑色的部份其值介>0並且 <=1。然後由這些點計算出迴歸線,所以就有a及b二個參數(y=ax+b)。回歸線就是把二維的資料減少成一條線來表示。
MLP 模型
摸型中先使用Flatten層將28*28二維陣列平化展開成一維具784個元素(特徵點)的陣列。輸出使用softmax()函數,將結果分散在0~9之間10個數字。
訓練時,y_pred=model(train_data_sigmoid),其實就是調用 class Model 的 __call__()方法。那麼我們不就應該覆寫 __call__()嗎,怎麼覆寫 call()?? 因為 __call__()會先作一些事情,然後再調用 call()。所以我們只需覆寫 call() 即可。
請在專案下新增 MLP.py 檔,然後輸入如下代碼。