
scikit-learn
pip install scikit-learn
機器學習的首要工作,就是搜集資料。在sklern套件中的datasets模組,有許多資料可以供我們練習使用。使用datasets.load_xxx即可顯示可用的資訊,如下所示
datasets.load_digits()是要辨識手寫數字圖片是 0 到 9 中的哪一個數字。digits的keys()可得知有那些資訊可以搜集。
target為觀測的目標(01234….),共有1797個值,每個值都介於 0~9之間,可以使用 target.shape 列出共有 1797個觀測值。
data為每個觀測目標的資料,由data.shape可列出共有1797筆資料,每筆資料都是 List 格式, 這個 List 裏有64個數字
images為每個觀測目標的圖形,也一共有1797個圖片,其實就是將 data 的資料轉成 8*8 的二維List
DESCR屬性為資料的描述文件。
import pandas as pd
from sklearn import datasets
digits = datasets.load_digits()
# Get the keys of the `digits` data
print(digits.keys())
# Print out the data
print(digits.data)
# Print out the target values
print(digits.target)
# Print out the description of the `digits` data
print(digits.DESCR)
結果 :
dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])
[[ 0. 0. 5. ... 0. 0. 0.]
[ 0. 0. 0. ... 10. 0. 0.]
[ 0. 0. 0. ... 16. 9. 0.]
...
[0 1 2 ... 8 9 8]
.. _digits_dataset:
Optical recognition of handwritten digits dataset
--------------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 5620
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
This is a copy of the test set of the UCI ML hand-written digits datasets
https://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
The data set contains images of hand-written digits: 10 classes where
each class refers to a digit.
Preprocessing programs made available by NIST were used to extract
normalized bitmaps of handwritten digits from a preprinted form. From a
total of 43 people, 30 contributed to the training set and different 13
to the test set. 32x32 bitmaps are divided into nonoverlapping blocks of
4x4 and the number of on pixels are counted in each block. This generates
an input matrix of 8x8 where each element is an integer in the range
0..16. This reduces dimensionality and gives invariance to small
distortions.
For info on NIST preprocessing routines, see M. D. Garris, J. L. Blue, G.
T. Candela, D. L. Dimmick, J. Geist, P. J. Grother, S. A. Janet, and C.
L. Wilson, NIST Form-Based Handprint Recognition System, NISTIR 5469,
1994.
.. topic:: References
- C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their
Applications to Handwritten Digit Recognition, MSc Thesis, Institute of
Graduate Studies in Science and Engineering, Bogazici University.
- E. Alpaydin, C. Kaynak (1998) Cascading Classifiers, Kybernetika.
- Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin.
Linear dimensionalityreduction using relevance weighted LDA. School of
Electrical and Electronic Engineering Nanyang Technological University.
2005.
- Claudio Gentile. A New Approximate Maximal Margin Classification
Algorithm. NIPS. 2000.
digits.data
data裏共有1797筆資料,每筆資料有64個數。代表著8列8行個點,每個點的值為0~15共16種顏色。下面的代碼可以驗証。
from sklearn import datasets
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from MahalCv import MahalCv as cv
digits = datasets.load_digits()
x=digits.data[0]
for i in range(8):
for j in range(8):
print('%2d ' % x[i*8+j], end='')
print()
plt.imshow(digits.images[0], cmap='gray')
plt.show()
結果如下
00 00 05 13 09 01 00 00
00 00 13 15 10 15 05 00
00 03 15 02 00 11 08 00
00 04 12 00 00 08 08 00
00 05 08 00 00 09 08 00
00 04 11 00 01 12 07 00
00 02 14 05 10 12 00 00
00 00 06 13 10 00 00 00
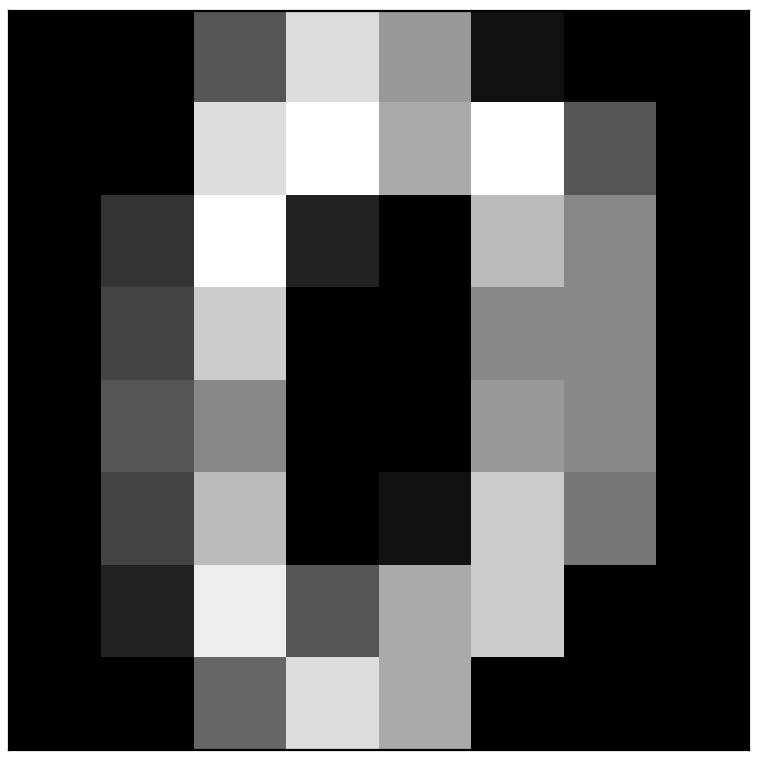
digits.images
digits.images 為1,797 個 8 x 8 像素的矩陣圖形資料。其實也就是 digits.data.reshape(1797,8,8) 的結果。
如下代碼可以將前100個圖形列出
from sklearn import datasets
import pylab as plt
digits=datasets.load_digits()
print(digits.data[0])
print(digits.images[0])
for i in range(100):
axes=plt.subplot(10,10,i+1)
axes.set_xticks([])
axes.set_yticks([])
axes.imshow(digits.images[i], cmap='gray')
plt.show()

參考 : https://www.datacamp.com/community/tutorials/scikit-learn-python