
優化器 -自適應梯度策略
優化器自適應梯度策略是常態損失函數的變型,改良常態損失函數的一些缺點或加快其收斂速度。
既然是常態損失函數的變型,那可以把優化器稱為 “變態損失函數” 嗎? 這絕對正確,因為它變型到非常猙獰,簡直到了變態的行為。
keras 官網 https://keras.io/zh/optimizers/ 介紹的的優化器有 RMSProp,AdaGrad,Adadelta,Adam,Adamax,Nadam。
自適應梯度通常有很複雜的演算及公式,一般人要用 Python 寫出其實有難度,所以都交給 tensorflow 包含在優化器中,直接調用即可。本篇說明 Ada、RMSP、Adam 三種優化器的公式及演算法。
Ada
Ada 是 Adaptive[əˋdæptɪv](自適應, 調節的) 的縮寫。
SGD 或動量在更新 x 值時,都是使用相同的學習率 (r)。而 Ada 則是每次的迭代,都會改變學習率,稱為學習率衰減(請注意喔,不是上面的衰減因子)。
Adagrad的公式如下 :
先計算 $(G_{t} = \sum_{t=1}^{n}f'(x_{t})^{2})$,也就是先計算每次導數平方總合
下一步的 x 標識為$(x_{t+1})$,其公式為 $(x_{t+1}=x_{t}-\frac{lr}{\sqrt{G_{t}}+\varepsilon}*f'(x_{t+1})=x_{t}-\frac{lr}{\sqrt{\sum_{t=1}^{n}f'(x_{t})^{2}}+\varepsilon}*f'(x_{t+1}))$
分母中的 $(\varepsilon)$ 是為了避免分母等於 0,稱為平滑項,一般設定為 1e-7。
Adagrad類別如下
import numpy as np
from MBGD import MBGD
class Adagrad(MBGD):
def __init__(self, a, b, x, y, lr, batch_size):
super().__init__(a, b, x, y, lr, batch_size)
self.sum_grad_a = 0
self.sum_grad_b = 0
# epsilon
self.e = 1e-6
def update(self):
self.a_old = self.a
self.b_old = self.b
grad_a, grad_b = self.gradient()
# 累加梯度平方和
self.sum_grad_a += grad_a ** 2
self.sum_grad_b += grad_b ** 2
# 梯度更新
self.a = self.a_old - (self.lr / (np.sqrt(self.sum_grad_a) + self.e)) * grad_a
self.b = self.b_old - (self.lr / (np.sqrt(self.sum_grad_b) + self.e)) * grad_b
loss = ((self.a * self.x + self.b) - self.y) ** 2
self.loss = np.mean(loss)
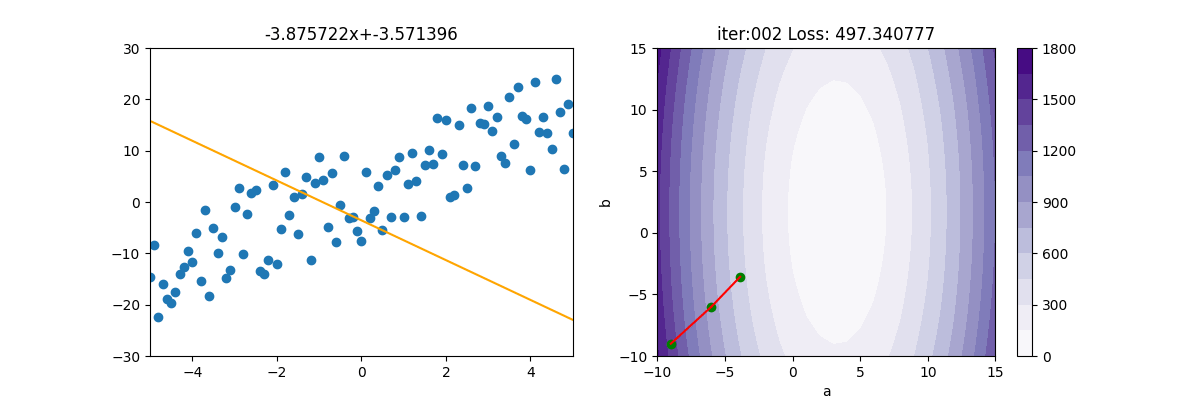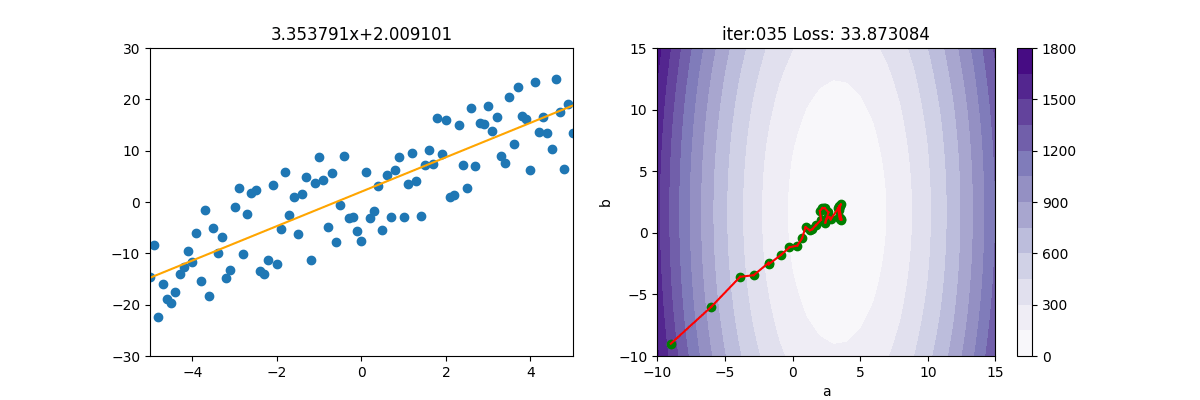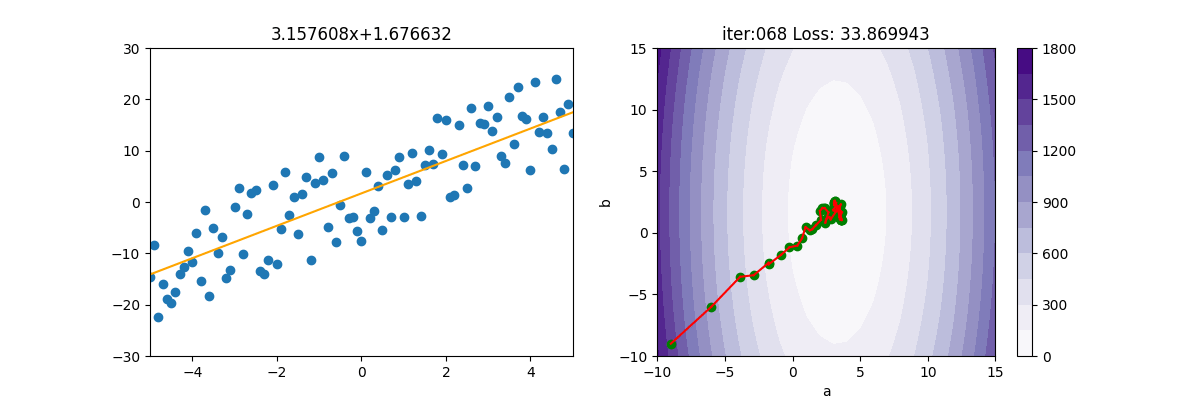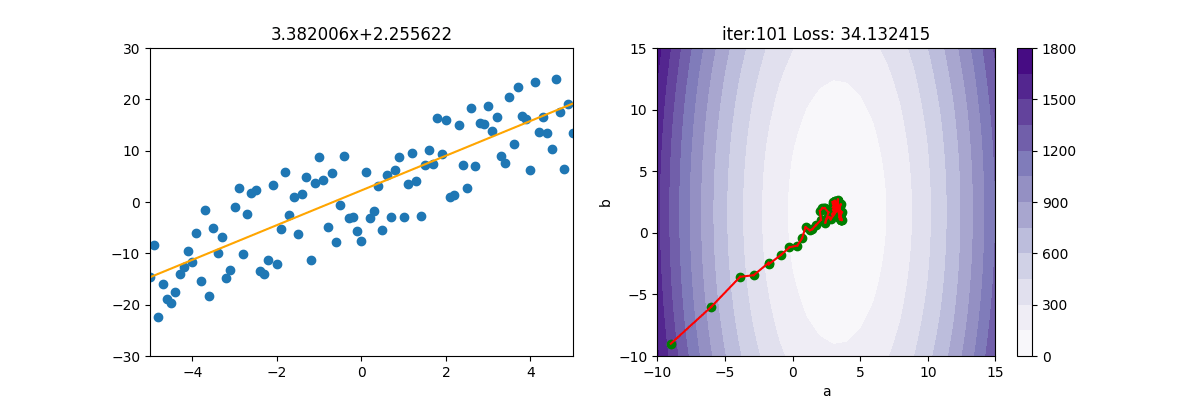
主程式如下
from Adagrad import Adagrad
from Regression import *
import pylab as plt
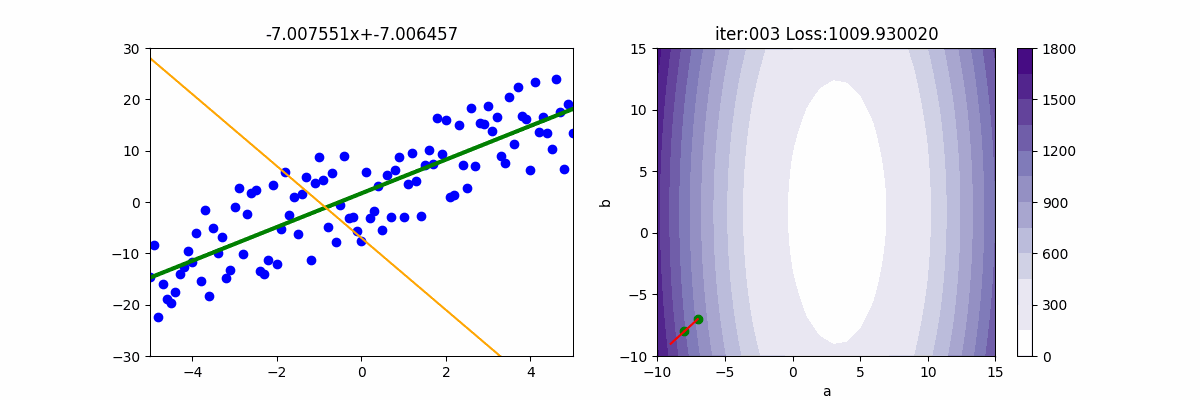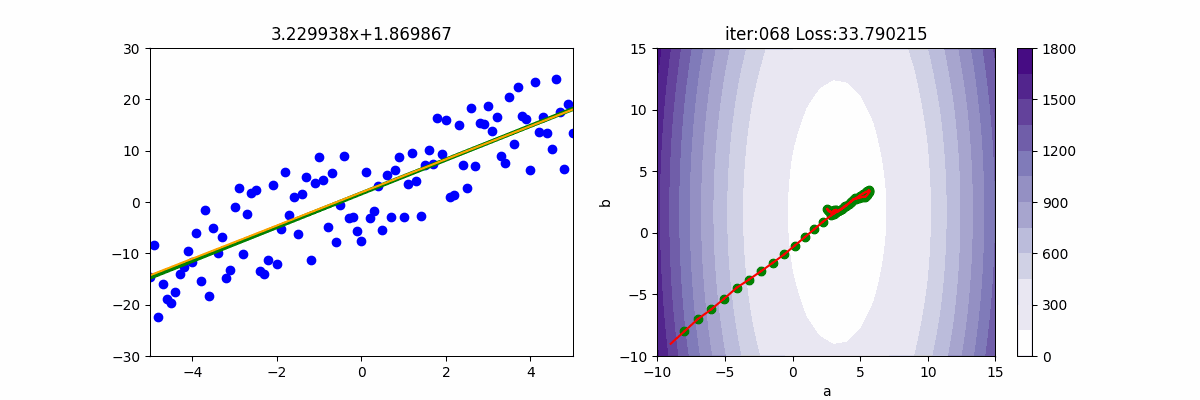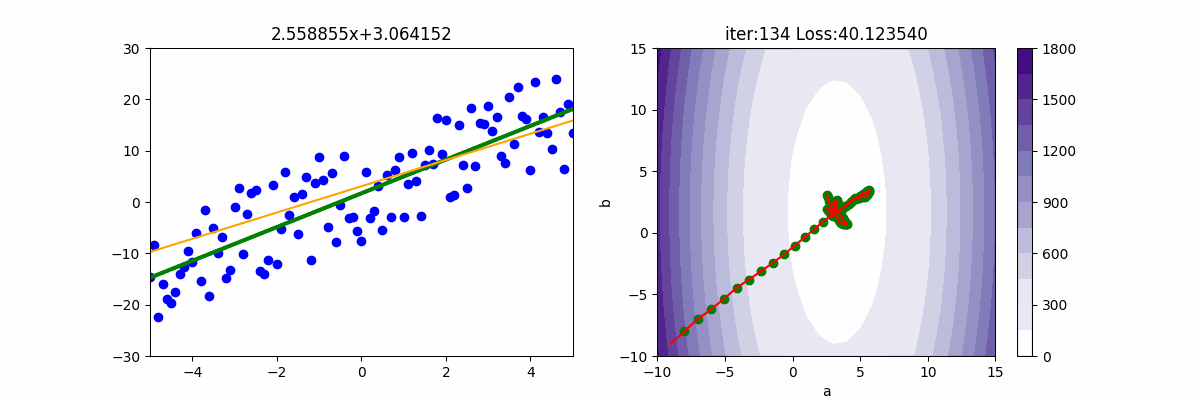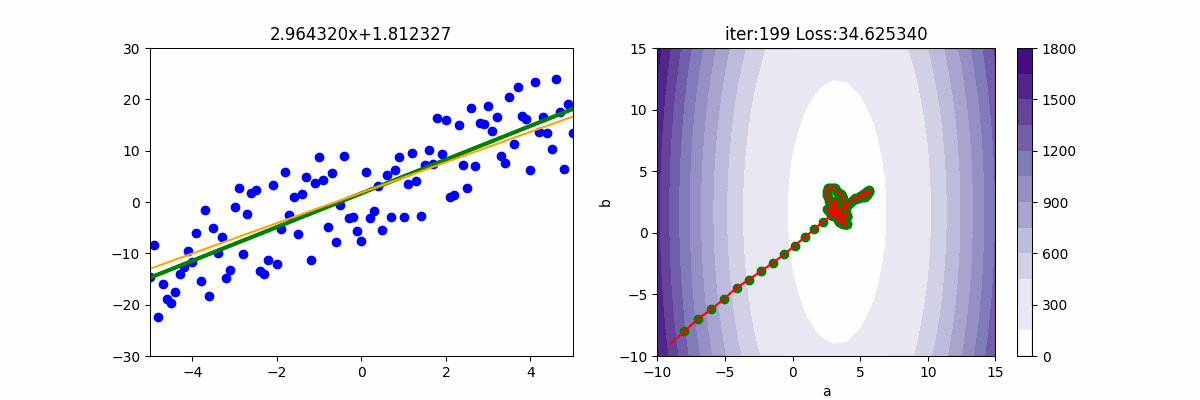
epoch=200
x,y=getData(100)
mesh, contour=getContour(x,y)
fig, ax=plt.subplots(nrows=1, ncols=2, figsize=(12,4))
a2=ax[1].contourf(mesh[0], mesh[1], contour, 15, cmap=plt.cm.Purples)
plt.colorbar(a2,ax=ax[1])
lr = 3
init_a = -9; init_b = -9
ax[1].scatter(init_a, init_b, c='g')
batch_size=25
gd = Adagrad(init_a, init_b, x, y, lr, batch_size)
for i in range(epoch):
gd.update()
ax[0].clear()
ax[0].set_xlim(-5, 5)
ax[0].set_ylim(-30, 30)
ax[0].scatter(x, y)
ax[0].plot([x[0], x[-1]], [gd.a * x[0] + gd.b, gd.a * x[-1] + gd.b], c="orange")
ax[0].set_title(f'{gd.a:.6f}x+{gd.b:.6f}')
print('iter=' + str(i) + ', loss=' + '{:.2f}'.format(gd.loss))
ax[1].set_xlim(-10,15)
ax[1].set_ylim(-10, 15)
ax[1].set_title(f'iter:{i+1:03d} Loss: {gd.loss:6f}')
ax[1].plot([gd.a_old, gd.a], [gd.b_old, gd.b], c='r')
ax[1].scatter(gd.a, gd.b, c='g')
ax[1].set_xlabel("a")
ax[1].set_ylabel("b")
plt.pause(0.01)
plt.show()
RMSP
RMSP 是 Root Mean Square Propagation[͵prɑpəˋgeʃən] 均方根傳播法的縮寫。
RMSP 就是 Ada 的改良,依梯度大小對學習率進行加強或衰減,比 Ada 更快進入收斂。
RMSP 的公式如下 :
$(G_{t+1}=\rho G_{t}+(1-\rho)f'(x_{t+1})^2)$,其中的 $(\rho)$ 一般設定為 0.9
RMSP類別繼承Adagrad類別,程式碼如下
from Adagrad import Adagrad
import numpy as np
class RMSP(Adagrad):
def __init__(self, a, b, x, y, lr, batch_size, rho):
super().__init__(a, b, x, y, lr, batch_size)
self.rho = rho
def update(self):
self.a_old = self.a
self.b_old = self.b
grad_a, grad_b = self.gradient()
self.sum_grad_a = self.rho * self.sum_grad_a + (1 - self.rho) * grad_a ** 2
self.sum_grad_b = self.rho * self.sum_grad_b + (1 - self.rho) * grad_b ** 2
self.a = self.a_old - (self.lr / (np.sqrt(self.sum_grad_a) + self.e)) * grad_a
self.b = self.b_old - (self.lr / (np.sqrt(self.sum_grad_b) + self.e)) * grad_b
loss = ((self.a * self.x + self.b) - self.y) ** 2
self.loss = np.mean(loss)
主程式同Adagrad,只是 lr 不同,並加了 rho參數
from Adagrad import Adagrad
from RMSP import RMSP
from Regression import *
import pylab as plt
epoch=200
x,y=getData(100)
mesh, contour=getContour(x,y)
fig, ax=plt.subplots(nrows=1, ncols=2, figsize=(12,4))
a2=ax[1].contourf(mesh[0], mesh[1], contour, 15, cmap=plt.cm.Purples)
plt.colorbar(a2,ax=ax[1])
lr = 0.2
init_a = -9; init_b = -9
ax[1].scatter(init_a, init_b, c='g')
batch_size=25
rho=0.9
gd = RMSP(init_a, init_b, x, y, lr, batch_size, rho)
for i in range(epoch):
gd.update()
ax[0].clear()
ax[0].set_xlim(-5, 5)
ax[0].set_ylim(-30, 30)
ax[0].scatter(x, y)
ax[0].plot([x[0], x[-1]], [gd.a * x[0] + gd.b, gd.a * x[-1] + gd.b], c="orange")
ax[0].set_title(f'{gd.a:.6f}x+{gd.b:.6f}')
print('iter=' + str(i) + ', loss=' + '{:.2f}'.format(gd.loss))
ax[1].set_xlim(-10,15)
ax[1].set_ylim(-10, 15)
ax[1].set_title(f'iter:{i+1:03d} Loss: {gd.loss:6f}')
ax[1].plot([gd.a_old, gd.a], [gd.b_old, gd.b], c='r')
ax[1].scatter(gd.a, gd.b, c='g')
ax[1].set_xlabel("a")
ax[1].set_ylabel("b")
plt.pause(0.01)
plt.show()
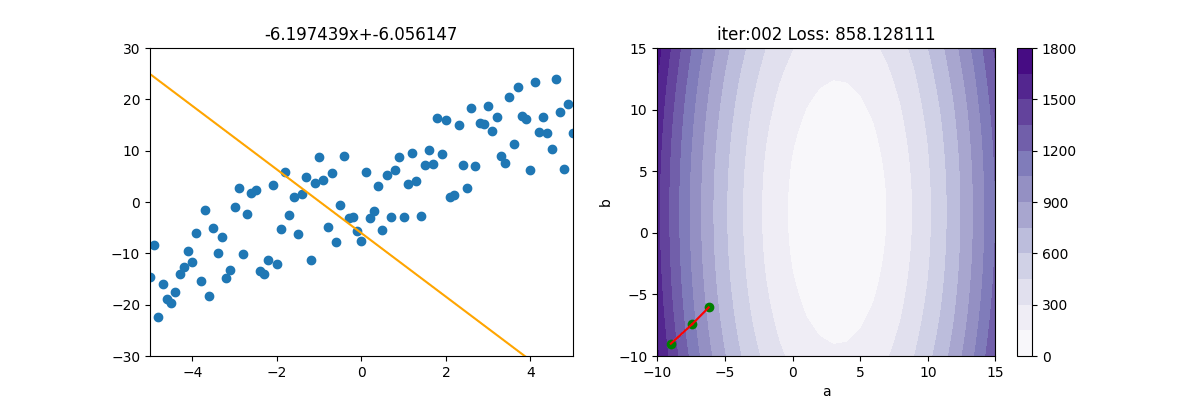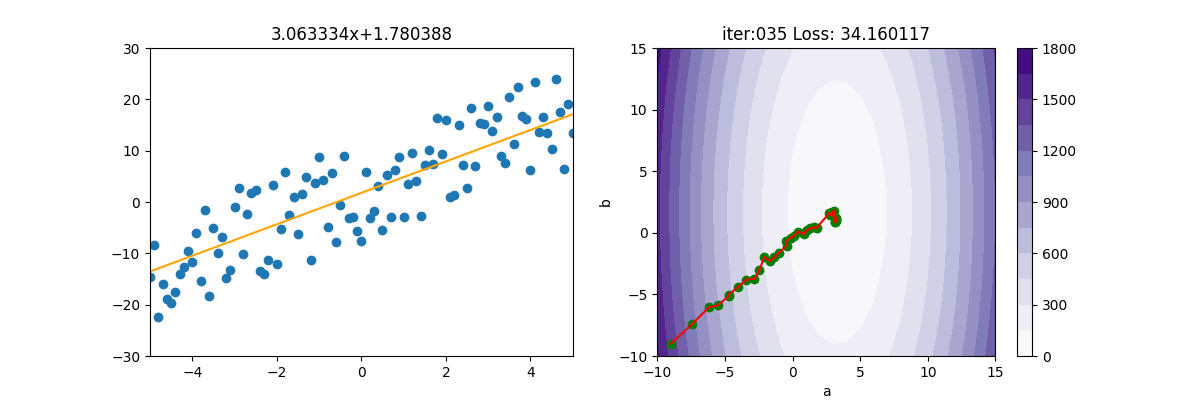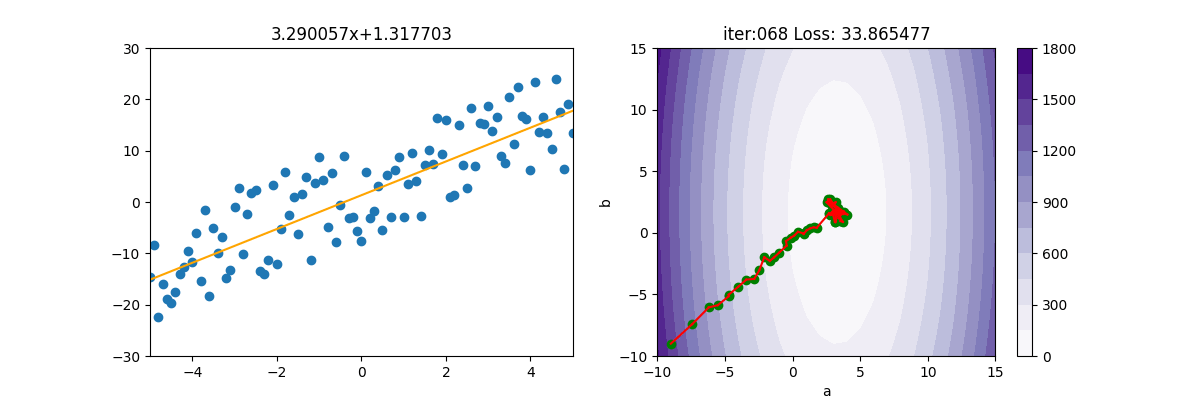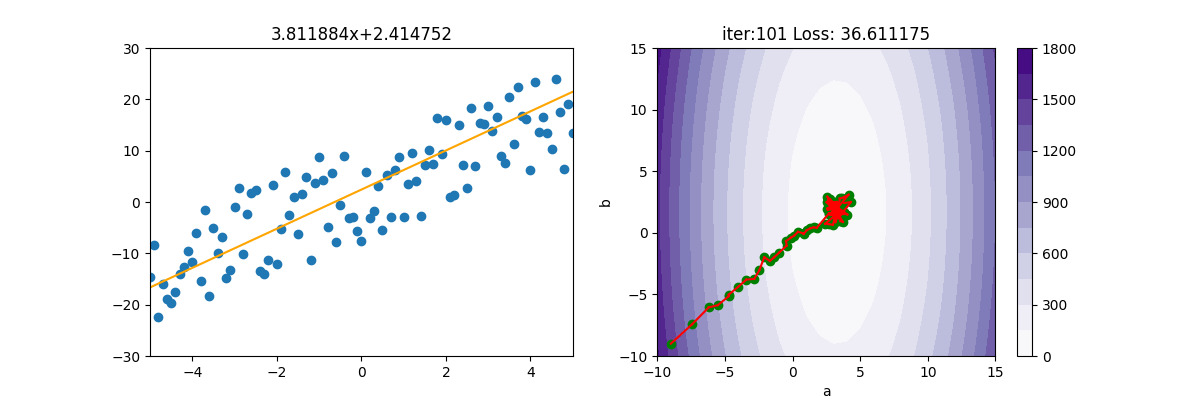
Adam
Adam 是 RMSP 加上動量的改良版,而 RMPS 又源自於 Ada 的改良版。也就是說 Ada => RMSP => Adam,所以名稱以 Ada + M = Adam。
那為什麼不用 RMSPM 這個名稱呢? 因為 Adam 有 $(\beta_{1})$ 及 $(\beta_{2})$ 二個參數,也就是多了 $(\beta_{2})$ 這個參數,這跟 RMSP 完全不同,所以只能說 Adam 是 Ada 及 RMSP 二者的進化版。
$(m_{t} = \beta_{1} m_{t-1}+(1-\beta_{1})f'(x_{t}))$
$(v_{t} = \beta_{2} v_{t-1}+(1-\beta_{2})f'(x_{t})^2)$
$(\beta_{1})$ 及 $(\beta_{2})$ 是二個接近 1 的值,一般 $(\beta_{1})$ 設定為 0.9, $(\beta_{2})$ 設定為 0.999。
然後要進行修正
$(\tilde{m}_{t} = \frac{m_{t}}{1-\beta_{1}^{t}})$,裏面的$(\beta_{1}^{t})$ 是 $(\beta_{1})$ 的 t 次方
$(\tilde{v}_{t} = \frac{v_{t}}{1-\beta_{2}^{t}})$,裏面的$(\beta_{2}^{t})$ 是 $(\beta_{2})$ 的 t 次方
$(x_{t+1} = x_{t}- \frac{lr}{\sqrt{\tilde{v}_{t}}+\varepsilon}\tilde{m}_{t})$
底下的代碼,Adam 類別繼承 MBGD
import numpy as np from MBGD import MBGD class Adam(MBGD): def __init__(self, a, b, x, y, lr, batch_size, beta1, beta2): super().__init__(a,b, x, y, lr, batch_size) self.beta1 = beta1 self.beta2 = beta2 self.e = 1e-6 self.sum_ma=0 self.sum_mb=0 self.sum_grad_a = 0 self.sum_grad_b = 0 def update(self, t): self.a_old = self.a self.b_old = self.b grad_a, grad_b = self.gradient() # 累加動量 self.sum_ma = self.beta1 * self.sum_ma + (1 - self.beta1) * grad_a self.sum_mb = self.beta1 * self.sum_mb + (1 - self.beta1) * grad_b self.sum_grad_a = self.beta2 * self.sum_grad_a + (1 - self.beta2) * grad_a ** 2 self.sum_grad_b = self.beta2 * self.sum_grad_b + (1 - self.beta2) * grad_b ** 2 #底下是修正用的,只要用區域變數即可,不必儲存 ma = self.sum_ma / (1 - np.power(self.beta1, t)) mb = self.sum_mb / (1 - np.power(self.beta1, t)) va = self.sum_grad_a / (1-np.power(self.beta2, t)) vb = self.sum_grad_b / (1 - np.power(self.beta2, t)) # 梯度更新 self.a -= (self.lr * ma) / (np.sqrt(va) + self.e) self.b -= (self.lr * mb) / (np.sqrt(vb) + self.e) loss=((self.a * self.x + self.b) - self.y) ** 2 self.loss=np.mean(loss)
主程式如下
from Adagrad import Adagrad from Adam import Adam from RMSP import RMSP from Regression import * import pylab as plt epoch=150 x,y=getData(100) mesh, contour=getContour(x,y) fig, ax=plt.subplots(nrows=1, ncols=2, figsize=(12,4)) a2=ax[1].contourf(mesh[0], mesh[1], contour, 15, cmap=plt.cm.Purples) plt.colorbar(a2,ax=ax[1]) lr = 1 init_a = -9; init_b = -9 ax[1].scatter(init_a, init_b, c='g') batch_size=25 beta1=0.9 beta2=0.999 gd = Adam(init_a, init_b, x, y, lr, batch_size, beta1, beta2) for i in range(epoch): gd.update(i+1) ax[0].clear() ax[0].set_xlim(-5, 5) ax[0].set_ylim(-30, 30) ax[0].scatter(x, y) f=np.poly1d(np.polyfit(x,y,1)) ax[0].plot(x, f(x),c='g', linewidth=3) ax[0].plot([x[0], x[-1]], [gd.a * x[0] + gd.b, gd.a * x[-1] + gd.b], c="orange") ax[0].set_title(f'{gd.a:.6f}x+{gd.b:.6f}') print('iter=' + str(i) + ', loss=' + '{:.2f}'.format(gd.loss)) ax[1].set_xlim(-10,15) ax[1].set_ylim(-10, 15) ax[1].set_title(f'iter:{i+1:03d} Loss: {gd.loss:6f}') ax[1].plot([gd.a_old, gd.a], [gd.b_old, gd.b], c='r') ax[1].scatter(gd.a, gd.b, c='g') ax[1].set_xlabel("a") ax[1].set_ylabel("b") plt.pause(0.01) plt.show()
參考資料
編譯 keras 模型至少需要二個參數,第一個是指定損失函數類型,第二個則是指定優化器 (optimizer) :
from keras import optimizers
model = Sequential()
model.add(Dense(64, kernel_initializer='uniform', input_shape=(10,)))
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='mean_squared_error', optimizer=sgd)
先產生一個實體優化器物件,然後將它傳入 model.compile(),像上述示例中一樣, 可以通過名稱來調用優化器。在後一種情況下,將使用優化器的默認參數。
# 傳入優化器名稱: 默認參數將被採用
model.compile(loss='mean_squared_error', optimizer='sgd')
Keras 優化器的公共參數
參數 clipnorm 和 clipvalue 能在所有的優化器中使用,用於控制梯度裁剪(Gradient Clipping):
from keras import optimizers
# 所有參數梯度將被裁剪,讓其l2範數最大為1:g * 1 / max(1, l2_norm)
sgd = optimizers.SGD(lr=0.01, clipnorm=1.)
from keras import optimizers
# 所有參數d 梯度將被裁剪到數值範圍內:
# 最大值0.5
# 最小值-0.5
sgd = optimizers.SGD(lr=0.01, clipvalue=0.5)
SGD
keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False)
隨機梯度下降優化器。
包含擴展功能的支援: – 動量(momentum)優化, – 學習率衰減(每次參數更新後) – Nestrov 動量 (NAG) 優化
參數
- lr: float >= 0. 學習率。
- momentum: float >= 0. 參數,用於加速 SGD 在相關方向上前進,並抑制震盪。
- decay: float >= 0. 每次參數更新後學習率衰減值。
- nesterov: boolean. 是否使用 Nesterov 動量。
RMSprop
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0)
RMSProp 優化器.
建議使用優化器的默認參數 (除了學習率 lr,它可以被自由調節)
這個優化器通常是訓練迴圈神經網路RNN的不錯選擇。
參數
- lr: float >= 0. 學習率。
- rho: float >= 0. RMSProp梯度平方的移動均值的衰減率.
- epsilon: float >= 0. 模糊因數. 若為None, 默認為 epsilon()。
- decay: float >= 0. 每次參數更新後學習率衰減值。
Adagrad
keras.optimizers.Adagrad(lr=0.01, epsilon=None, decay=0.0)
Adagrad 優化器。
Adagrad 是一種具有特定參數學習率的優化器,它根據參數在訓練期間的更新頻率進行自我調整調整。參數接收的更新越多,更新越小。
建議使用優化器的默認參數。
參數
- lr: float >= 0. 學習率.
- epsilon: float >= 0. 若為None, 默認為 epsilon().
- decay: float >= 0. 每次參數更新後學習率衰減值.
Adadelta
keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=None, decay=0.0)
Adadelta 優化器。
Adadelta 是 Adagrad 的一個具有更強魯棒性的的擴展版本,它不是累積所有過去的梯度,而是根據漸變更新的移動視窗調整學習速率。 這樣,即使進行了許多更新,Adadelta 仍在繼續學習。 與 Adagrad 相比,在 Adadelta 的原始版本中,您無需設置初始學習率。 在此版本中,與大多數其他 Keras 優化器一樣,可以設置初始學習速率和衰減因數。
建議使用優化器的默認參數。
參數
- lr: float >= 0. 學習率,建議保留預設值。
- rho: float >= 0. Adadelta梯度平方移動均值的衰減率。
- epsilon: float >= 0. 模糊因數. 若為None, 默認為 epsilon()。
- decay: float >= 0. 每次參數更新後學習率衰減值。
Adam
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
Adam 優化器。
默認參數遵循原論文中提供的值。
參數
- lr: float >= 0. 學習率。
- beta_1: float, 0 < beta < 1. 通常接近於 1。
- beta_2: float, 0 < beta < 1. 通常接近於 1。
- epsilon: float >= 0. 模糊因數. 若為None, 默認為 epsilon()。
- decay: float >= 0. 每次參數更新後學習率衰減值。
- amsgrad: boolean. 是否應用此演算法的 AMSGrad 變種,來自論文 “On the Convergence of Adam and Beyond”。
Adamax
keras.optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0)
Adamax 優化器,來自 Adam 論文的第七小節.
它是Adam演算法基於無窮範數(infinity norm)的變種。 默認參數遵循論文中提供的值。
參數
- lr: float >= 0. 學習率。
- beta_1/beta_2: floats, 0 < beta < 1. 通常接近於 1。
- epsilon: float >= 0. 模糊因數. 若為None, 默認為 epsilon()。
- decay: float >= 0. 每次參數更新後學習率衰減值。
Nadam
keras.optimizers.Nadam(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, schedule_decay=0.004)
Nesterov 版本 Adam 優化器。
正像 Adam 本質上是 RMSProp 與動量 momentum 的結合, Nadam 是採用 Nesterov momentum 版本的 Adam 優化器。
默認參數遵循論文中提供的值。 建議使用優化器的默認參數。
參數
- lr: float >= 0. 學習率。
- beta_1/beta_2: floats, 0 < beta < 1. 通常接近於 1。
- epsilon: float >= 0. 模糊因數. 若為None, 默認為 epsilon()。