
神經網路(Neural Network)
神經元是人類腦部儲存資訊的基本功能單元,裏面又分為細胞体,樹突(接收体),軸突(傳遞功能)。所以一個神經元可儲存一個單位的資料。人類的神經元約有860億個(86G)。不過每個神經元可以儲存幾個byte, 應該還沒研究出來。假設每個神經元可以儲存1000byte, 那麼人類應該有86G*1000=86T byte的容量(嗯,86顆1T的硬碟)。只是好玩,粗步假設一下而以,別當真啦,本人覺的應該不止這個數字。
假設要辨識一張圖片,則每一個像素都是一個特徵,也就是說,每一個像素都是一個神經元。但一張圖的像素這麼多,如何如何有效的減少這些像素數量,形成第二層神經層,就是目前的工作。
神經網路由三個部分組成,分別是輸入層(Input Layers)、隱藏層(Hidden Layers)以及輸出層 (Output Layers)。
輸入層
就是輸入資料(Data)的特徵值 (Features),舉個例來說,今天要預測一個人是男生還是女生,可以依照這個人的身高、體重、髮長等特徵來判斷,將這些特徵輸入,就是輸入層的工作。
隱藏層
隱藏層就是進行運算的工作,由神經元(Neuron)組成,透過前向傳播(Forward propagation) 計算出我們的輸出值。
輸出層
而輸出層為經由隱藏層運算後所得到的預測值,並經由縮小預測值與實際值的差異,然後更新隱藏層的參數,最後訓練出一組權重(weights)
CNN
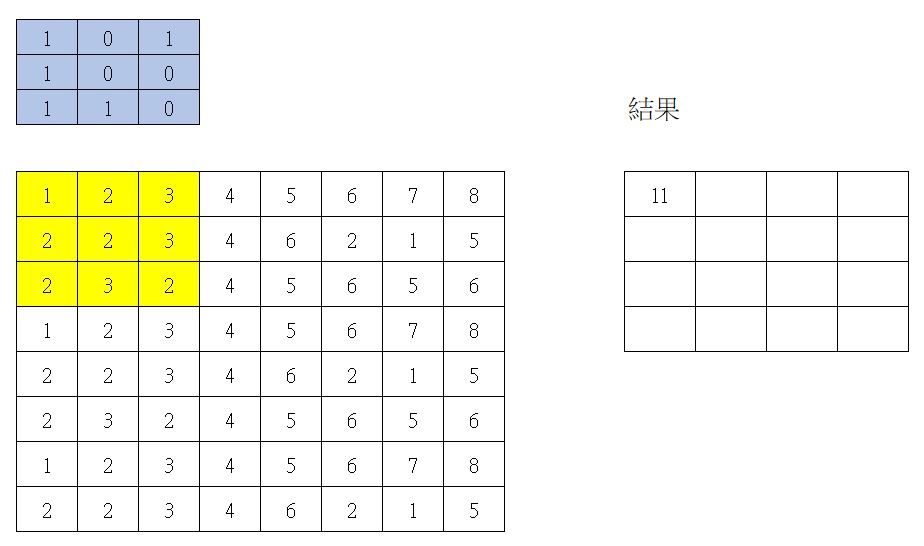
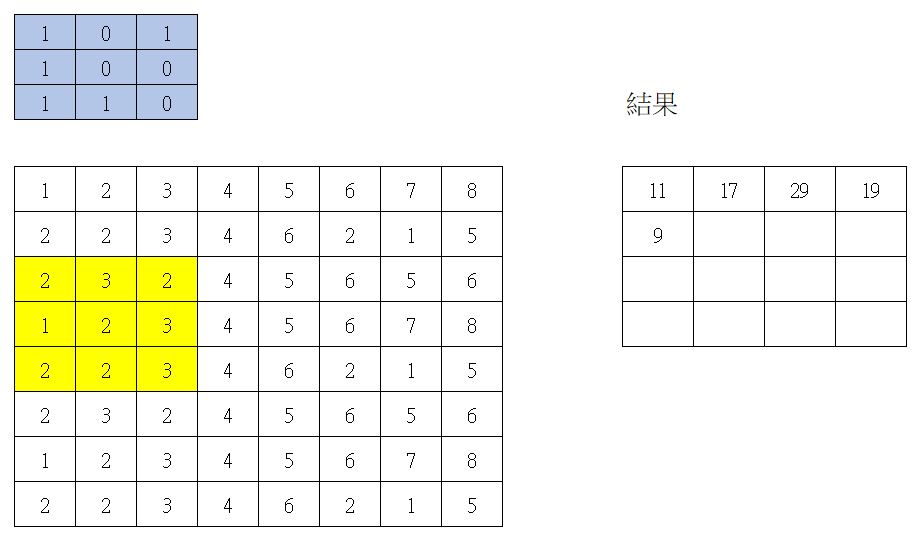
Convolutional Neural Network,卷積神經網路,好一個奇怪的名詞。意思是找一個長寬固定的過濾片(如3*3),然後與圖片上所有的點作內積。這個Filter又稱為kernel。捲積圖解如下
第一次捲積
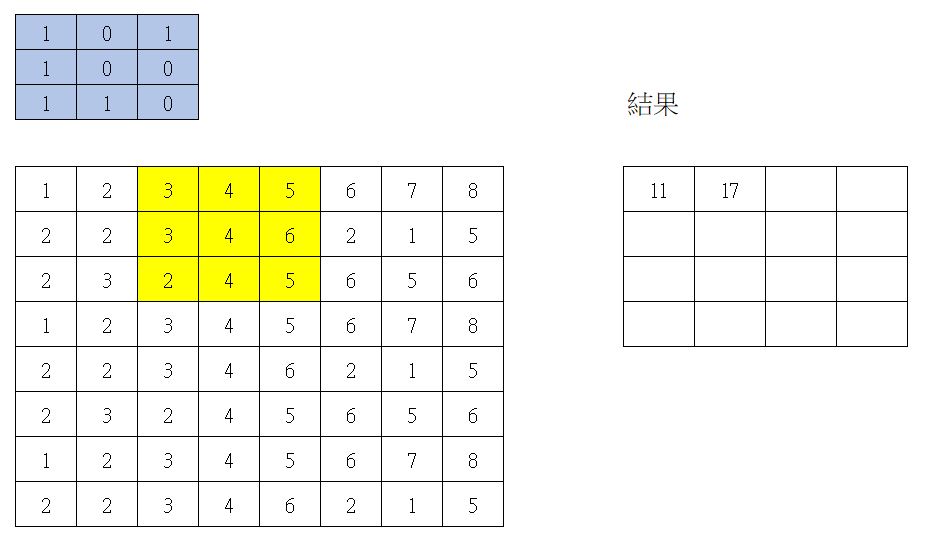
第二次捲積
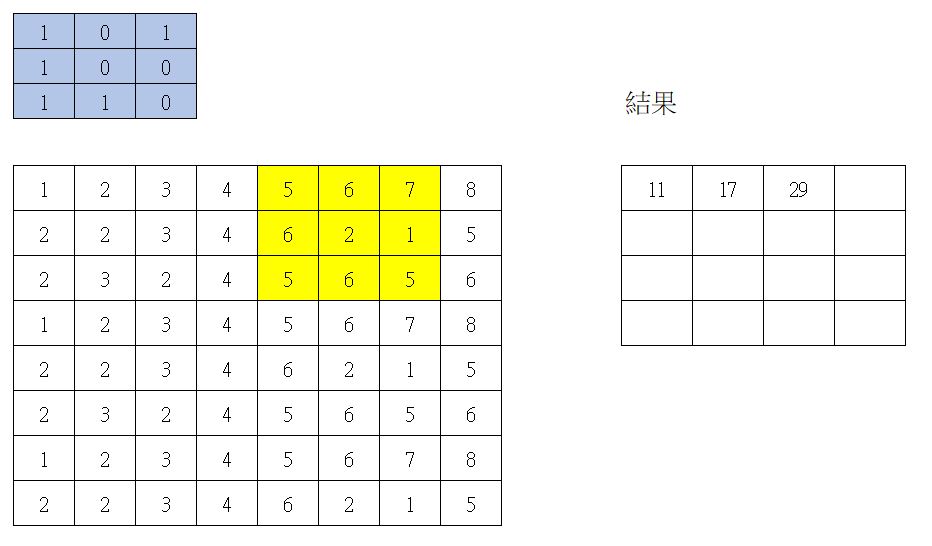
第三次捲積
第四次捲積
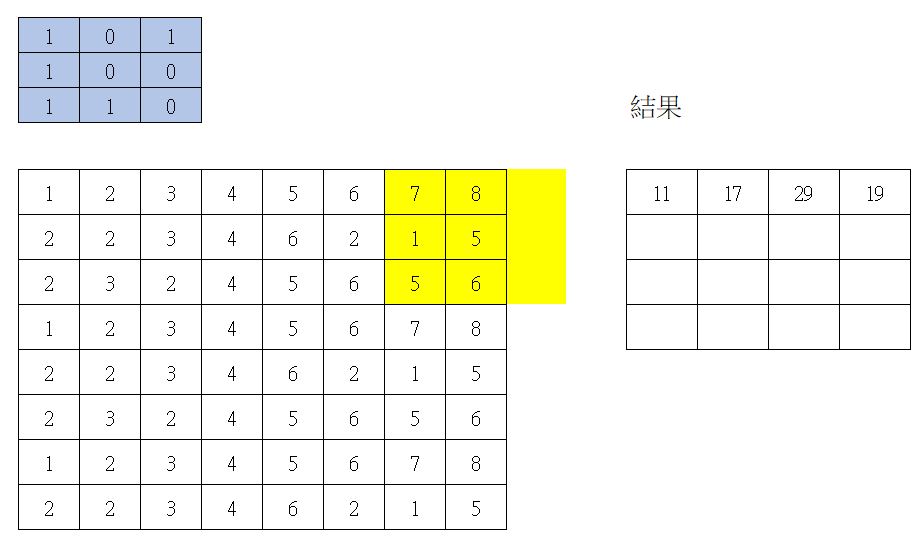
第五次捲積
最後一次捲積
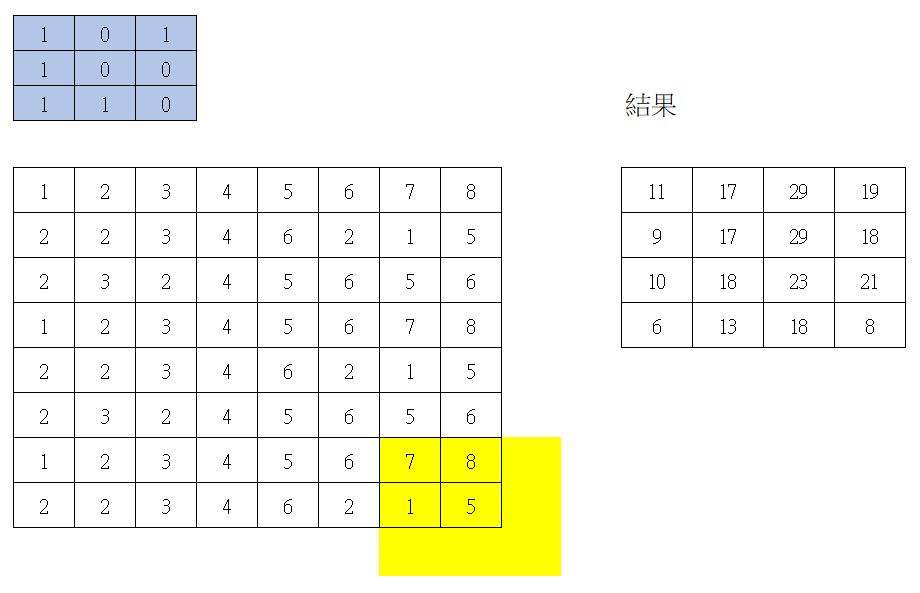
所以原本資料有 8 * 8 = 64個值,捲積 strides = 2 時,就會產生 4 * 4 = 16個值。
通常,Filter是一大堆。假設有100個Filter, 則就會產生 4*4*100=1600個值。
CNN架構 : Convolution->Max Pooling->Convolution->MaxPooling_>Flatten->全連接層
Filter : 看全連接輸出層有幾個值,就有幾個filter,而Filter裏面的值,就是學習出來的。也就是我們訓練的目的。
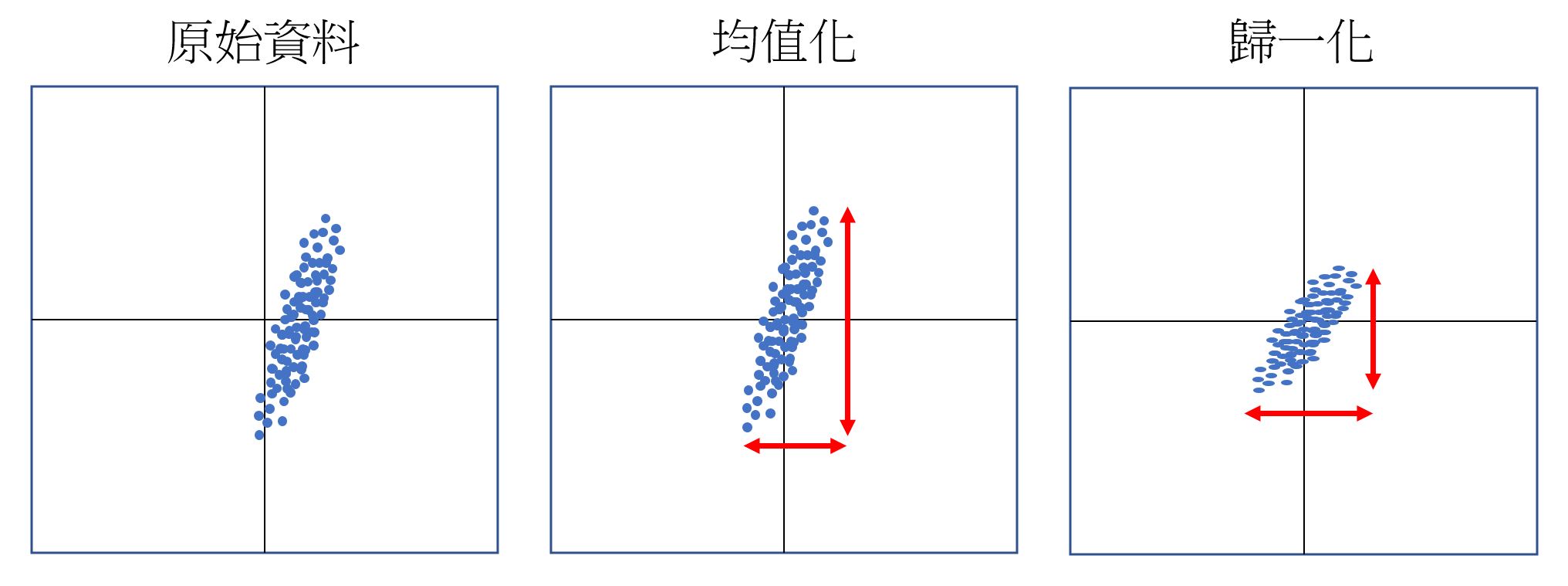
CNN輸入層
可以使用均值化,歸一化, PCA等方式。如下原始資料散佈在右邊。均值化是要把中心點移到(0,0)的位置。然後再把扁長的形狀歸一化,把長及寬各自限制在 -1~1之間
CNN隱藏層
CNN隱藏層又分為卷積層,活化層,池化層
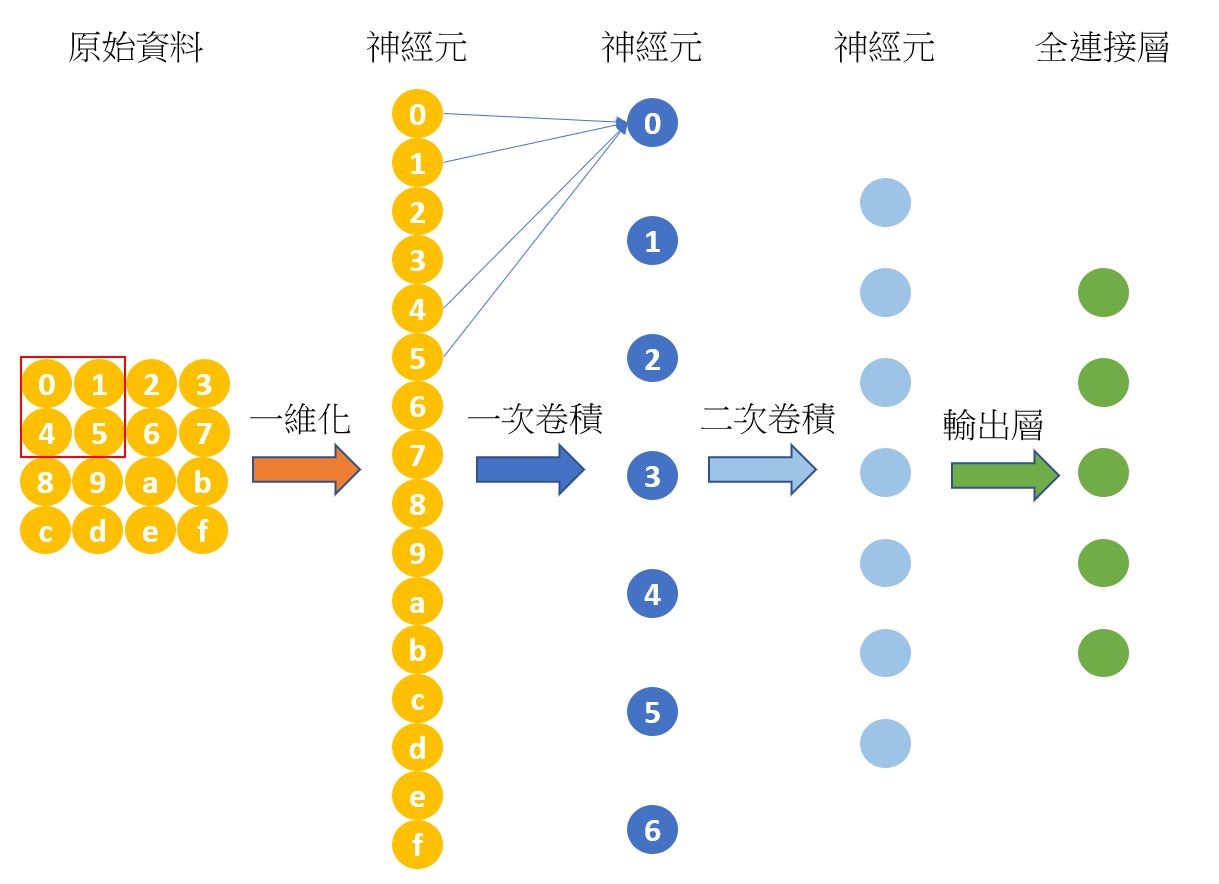
卷積層
卷積層為計算卷積的工作。首先將圖片的二維陣列資料一維化,一維化的資料稱為神經元。然後使用kernel卷積成一次卷積神經元。一維卷積亦可再次二次卷積,三次卷積…。最後產生全連接層。
kernel是的維度可以為3*3,5*5,7*7。最好是奇數格,因為奇數才有中心點。至於kernel裏的值是多少,這就是模型要訓練的目的了。
活化層
活化層常用幾個函數,如Sigmod(S函數),Tanh, ReLU, Leaky ReLU…..。為什麼要有活化層呢?? 因為經過上述卷積後,有可能某個元素的值變成了負值,也有可超出範圍值。但在圖形裏,像素的顏色值是介於0~255之間,不能有負值,也不能超出255。所以如何把負值給去除掉,就有上述的方法。如下代碼,就會產生負值。甚於是大於255以上。
from MahalCv import MahalCv as cv
import cv2
import numpy as np
img=cv.read('p4.jpg')
img=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img=cv.resize(img, scale=0.2)
h, w=img.shape
img=img.reshape(w*h)
k=np.array([[-1,0,1], [-1,0,0], [0,0,1]])
img=np.convolve(img, k.reshape(9), 'same')
img=img.reshape(h, w)
print(img)
結果 :
[[-230 -224 -220 ... -51 -1 -52]
[ -49 -56 -52 ... -50 1 -49]
[ -51 -53 -56 ... -54 -1 -50]
...
[ 19 20 17 ... 15 2 15]
[ 13 20 16 ... 14 -2 13]
[ 11 16 17 ... 77 1 80]]
如何把超出範圍的值挑出,又如何安排後續的值。下面圖形描述其方式
池化層
經過卷積及活化後所產生的特徵神經元,有些是多餘的資訊,此時就用池化層(pooling)將之去除掉。我們下採樣就是為了去掉這些冗餘信息,所以並不會損壞識別結果。去除多餘的資訊常用的有二種: Max pooling及Average pooling
Max pooling : 設定如 2*2格的窗口,然後在是四格之中,取最大的值,其它值就丟掉。
Average pooling : 比如以 2*2格的窗口,取這四格的平均值
CNN全連接層
通常全連接層在卷積神經網絡尾部。當前面卷積層抓取到足以用來識別圖片的特徵後,接下來的就是如何進行分類。 通常會將卷積網絡的末端得到的長方體平攤成一個一維的向量,並送入全連接層配合輸出層進行分類。比如手寫數字,總共有0~9共10個數字,所以卷積神經網絡的輸出層就會有10個神經元。
手寫數字預測
底下使用CNN預測手寫數字,可達到100%。底下的CNN第一層,因為strides為2,每次卷積步進為2, 所以就會由28*28變成14*14矩陣。第二次卷積,就會又變成7*7矩陣。
其實下面程式,經測試,只需卷積一次即可。不過扁平化需改成
self.flatten = tf.keras.layers.Reshape(target_shape=(14 * 14 * 32,))。
另外batch_size除了要看顯卡的記憶体大小外,也影響了逼近的次數。batch_size愈小,逼近的次數也會多,精準度也愈高。
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import numpy as np
import cv2
import pylab as plt
cpus = tf.config.list_physical_devices (device_type='CPU')
#tf.config.set_visible_devices (devices=cpus)
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = mnist.load_data()
# MNIST中的圖片預設為uint8(0-255的數字)。以下程式碼將其正規化到0-1之間的浮點數
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1)# [60000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32)# [60000]
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_data(self, batch_size, index):
s=index*batch_size
e=(index+1)*batch_size
return self.train_data[s:e], self.train_label[s:e]
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷積層神經元(卷積核)數目
kernel_size=[5, 5], # 接受區的大小
padding='same', # 大小寫敏感度(vaild 或 same)
activation=tf.nn.relu# 激活函数
)#共 14*14*32 = 6272個神經元
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)#共7*7*64 = 3136個神經元,是第一次捲積的一半
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs)# [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
#batch_size 每次訓練的資料量不能太大,不然GPU記憶体不足(超過2000個,視顯卡內存而定)
#且batch_size,造成num_batches太小,逼進次數太少而loss值太大
learning_rate = 0.001
batch_size = 500
model=CNN()
data_loader = MNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
num_batches = int(data_loader.num_train_data // batch_size)
for i in range(num_batches):
with tf.GradientTape() as tape:
X, y = data_loader.get_data(batch_size, i)
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("第%3d次逼進: loss %f" % (i+1, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
imgs=[]
for i in range(10):
img=cv2.imdecode(np.fromfile(f'{i}.jpg', dtype=np.uint8), cv2.IMREAD_UNCHANGED)
img=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img=cv2.resize(img, (28,28), interpolation=cv2.INTER_LINEAR)
imgs.append(img)
new_img=np.array(imgs)#預測資料的圖形
new_img=np.expand_dims(new_img.astype(np.float32) / 255.0, axis=-1)
new_true=np.array([0,1,2,3,4,5,6,7,8,9])#預測資料的標籤
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()#信心度測試器
new_pred=model.predict(new_img)#[[1,0,0,....0], [0,1,0,0,.....0]......]
new_target=np.argmax(new_pred, axis=-1)#轉成實際的數字
sparse_categorical_accuracy.update_state(y_true=new_true, y_pred=new_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
for i in range (10):
axes = plt.subplot(1, 10, i + 1)
axes.set_xticks([])
axes.set_yticks([])
axes.set_title(new_target[i], fontproperties='Simsun')
axes.imshow(new_img[i], cmap='gray')
plt.show()
結果:
第117次逼進 : loss 0.031104
第118次逼進 : loss 0.032790
第119次逼進 : loss 0.037868
第120次逼進 : loss 0.137415
測試精準度(accuracy): 1.000000