
本篇使用 LSTM 模型分析及預測黃金期貨價格,資料可由 yfinance 或本站資料庫取得。
關連式資料表
可以使用如下關連式資料表簡化表格制作,讓黃金價格最後有美元指標及原油價格。
conn, cursor=G.connect()
stock="GC=F"
shift=7
cursor.execute(f"select 名稱 from 股票代號 where 代號 ='{stock}'")
title=cursor.fetchall()[0][0]
cmd=f"""
select
a.日期 as 日期,
a.開盤 as 開盤,
a.最高 as 最高,
a.最低 as 最低,
a.收盤 as 收盤,
a.成交量 as 成交量,
b.收盤 as 美元,
c.收盤 as 原油
from (台灣股市 a join 台灣股市 b on a.日期=b.日期) join 台灣股市 c on a.日期=c.日期
where a.代號='{stock}' and b.代號='DX-Y.NYB' and c.代號 ='CL=F'
order by a.日期
"""
cursor.execute(cmd)
rs=cursor.fetchall()
columns=[d[0] for d in cursor.description]
df=pd.DataFrame(rs,columns=columns)
模型訓練
MinMaxScaler 是每筆資料除以最大值,產生介於 0~1 之間的資料,這樣在 sigmoid 時輸出 0~1 之間的預測。若沒有 MinMaxScaler,會產生梯度爆炸、梯度消失、Loss 不穩、收斂很慢。MinMaxScaler 的公式如下。
$(scaler = \frac{x_{i}-min}{max-min})$
shift : 由前 shift 天的價格預測明天,但黃金或股市的躁音太大,shift 不要太大。
batch_size 設定為 16 較為精準 : 金融時間序列,太大會造成更新太慢、泛化較差。
units : 為 LSTM 模型內的神經元數量。股市為 noisy data,units 太大會過度擬合,記住雜訊,測試出 128 為較準確的參數。
新版模型加入 [開盤, 最高, 最低, 收盤價, 成交量] 五個特徵進行訓練。
完整代碼如下。
#pip install mysql-connector-python tensorflow scikit-learn pandas plotly
from keras import Sequential
from keras.src.layers import LSTM, Dropout, Dense
from sklearn.preprocessing import MinMaxScaler
from G import G
import pandas as pd
import numpy as np
conn, cursor=G.connect()
stock="GC=F"
shift=7
cursor.execute(f"select 名稱 from 股票代號 where 代號 ='{stock}'")
title=cursor.fetchall()[0][0]
cmd=f"""
select
a.日期 as 日期,
a.開盤 as 開盤,
a.最高 as 最高,
a.最低 as 最低,
a.收盤 as 收盤,
a.成交量 as 成交量,
b.收盤 as 美元,
c.收盤 as 原油
from (台灣股市 a join 台灣股市 b on a.日期=b.日期) join 台灣股市 c on a.日期=c.日期
where a.代號='{stock}' and b.代號='DX-Y.NYB' and c.代號 ='CL=F'
order by a.日期
"""
cursor.execute(cmd)
rs=cursor.fetchall()
columns=[d[0] for d in cursor.description]
df=pd.DataFrame(rs,columns=columns)
#features=["開盤","最高","最低","收盤","成交量","美元"]
features=["收盤","美元", "原油"]
scaler=MinMaxScaler()
df[features]=scaler.fit_transform(df[features])
x=[]
y=[]
for i in range(len(df)-shift):
x.append(
df[features].iloc[i:i+shift].values
)
y.append(
df["收盤"].iloc[i+shift]
)
train_x=np.array(x)
train_y=np.array(y)
model=Sequential()
model.add(
LSTM(
input_shape=(shift, len(features)),
units=128,
#unroll=False
)
)
model.add(Dropout(0.2))
model.add(Dense(1))
model.compile(
loss="mse",
optimizer="adam",
metrics=["mae"]
)
model.fit(
train_x, train_y,
batch_size=16,
epochs=200,
verbose=1,
)
model.save(f"{title}_{shift}.keras")
預測
預測隔日黃金價格完整代碼如下。
from datetime import timedelta
from keras.src.saving import load_model
from sklearn.preprocessing import MinMaxScaler
import plotly.graph_objects as go
from G import G
import pandas as pd
import numpy as np
conn, cursor=G.connect()
stock="GC=F"
shift=7
cursor.execute(f"select 名稱 from 股票代號 where 代號 ='{stock}'")
title=cursor.fetchall()[0][0]
cmd=f"""
select
a.日期 as 日期,
a.開盤 as 開盤,
a.最高 as 最高,
a.最低 as 最低,
a.收盤 as 收盤,
a.成交量 as 成交量,
b.收盤 as 美元,
c.收盤 as 原油
from (台灣股市 a join 台灣股市 b on a.日期=b.日期) join 台灣股市 c on a.日期=c.日期
where a.代號='{stock}' and b.代號='DX-Y.NYB' and c.代號 ='CL=F'
order by a.日期
"""
cursor.execute(cmd)
rs=cursor.fetchall()
columns=[d[0] for d in cursor.description]
df=pd.DataFrame(rs,columns=columns)
df["實際價格"]=df["收盤"]
return_scaler=MinMaxScaler()
return_scaler.fit_transform(df[["收盤"]])
scaler=MinMaxScaler()
#features=["開盤","最高","最低","收盤","成交量","美元"]
features=["收盤","美元", "原油"]
df[features]=scaler.fit_transform(df[features])
model=load_model(f"{title}_{shift}.keras")
x=[]
for i in range(len(df)-shift+1):
x.append(
df[features].iloc[i:i+shift].values
)
train_x=np.array(x)
predict=model.predict(train_x)
df["日期"]=df["日期"].shift(-shift+1)
df["實際價格"]=df["實際價格"].shift(-shift+1)
df=df.dropna()
df["predict"]=return_scaler.inverse_transform(predict)
df["日期"]=df["日期"].shift(-1)
df["實際價格"]=df["實際價格"].shift(-1)
last=df.iloc[-2]["日期"]
last=last+ timedelta(days=1)
df.iloc[-1, df.columns.get_loc("日期")] = last
period=-200
fig=go.Figure()
fig.add_trace(
go.Scatter(
x=df["日期"][period:],
y=df["實際價格"][period:-1],
mode='lines',
name='實際價格',
line=dict(color='red', width=2)
)
)
fig.add_trace(
go.Scatter(
x=df["日期"][period:],
y=df["predict"][period:],
mode='lines',
name='預測價格',
line=dict(color='green', width=2)
)
)
fig.update_layout(
dragmode="pan",
title_text=f"{title}預測",
xaxis=go.layout.XAxis(
rangeselector=dict(
buttons=list([
dict(count=1,
label="1 month",
step="month",
stepmode="backward"),
dict(count=6,
label="6 month",
step="month",
stepmode="backward"),
dict(count=1,
label="1 year",
step="year",
stepmode="backward"),
dict(count=1,
label="1 day",
step="day",
stepmode="todate"),
dict(step="all")
])
),
rangeslider=dict(
visible=True
),
#range=[datetime.datetime(d.year, 1,1),datetime.datetime(d.year, d.month, d.day)],
type="date"
),
yaxis=dict(fixedrange=False)
)
#plotly.offline.plot(fig,filename="lstm.html", auto_open=False)
fig.show()
平均日線
底下使用 5 日均線及 10 日均線為特徵,輸入 LinearRegression 模型訓練後,預測下一日的值。
請先安裝如下套件
pip install plotly yfinance scikit-learn pandas
完整代碼如下
from datetime import datetime, timedelta
import pandas as pd
from dateutil.relativedelta import relativedelta
from sklearn.linear_model import LinearRegression
display=pd.options.display
display.max_columns=None
display.max_rows=None
display.width=None
display.max_colwidth=None
import yfinance as yf
import plotly.graph_objects as go
"""
大盤 : ^TWII
黃金期貨 : GC=F
"""
stock='GC=F'
df=yf.download(stock, start='2023-10-01', end='2024-05-12')
fig=go.Figure()
fig.add_trace(
go.Scatter(
x=df.index,
y=df['Close'].values,
mode='lines',
name='實際價格',
line=dict(color='royalblue', width=2)
)
)
ma1=5#5日平均線
ma2=10#10日平均線
df=df.dropna()
df['s1']=df['Close'].rolling(window=ma1).mean()
df['s2']=df['Close'].rolling(window=ma2).mean()
df=df.dropna()
train=df[['Close','s1','s2']]
train['next_day_price']=train['Close'].shift(-1)
train=train.dropna()
x_train=train[['s1', 's2']]
y_train=train['next_day_price']
model=LinearRegression()
model.fit(x_train, y_train)
df['predict_price']=model.predict(df[['s1', 's2']])
pred=df[['predict_price']]
s=(pred.tail(1).index+timedelta(days=1))[0]
dates=pd.date_range(s, periods=1)
pred.loc[dates[0]]=[0]
pred['predict_price']=pred['predict_price'].shift(1)
print(pred)
fig.add_trace(
go.Scatter(
x=pred.index,
y=pred['predict_price'].values,
mode='lines',
name='AI預測',
line=dict(color='orange', width=1)
)
)
current = datetime.now()
xrange = [(current - relativedelta(months=6)).strftime("%Y-%m-%d"), current.strftime("%Y-%m-%d")]
yrange = [df['Close'].tail(180).min(), df['Close'].tail(180).max()]
fig.update_layout(
dragmode="pan",
xaxis=go.layout.XAxis(
range=xrange,
rangeselector=dict(
buttons=list([
dict(count=1,
label="1 month",
step="month",
stepmode="backward"),
dict(count=6,
label="6 month",
step="month",
stepmode="backward"),
dict(count=1,
label="1 year",
step="year",
stepmode="backward"),
dict(count=1,
label="1 day",
step="day",
stepmode="todate"),
dict(step="all")
])
),
rangeslider=dict(
visible=True
),
type="date"
),
yaxis=dict(
fixedrange=False,
range=yrange
)
)
fig.show()
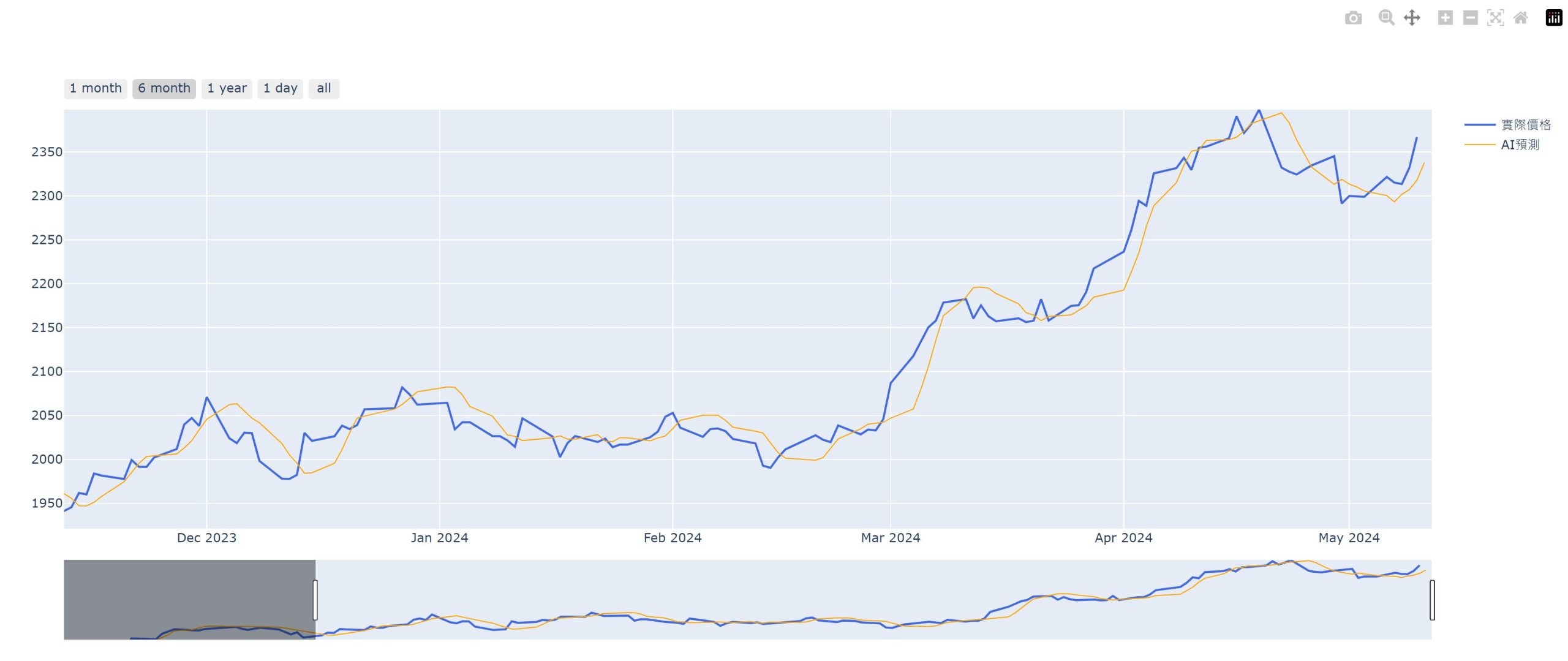
單一特徵模型及預測
底下是單一特徵(前幾天的收盤)的 LSTM,僅作記錄用。
訓練
#pip install pandas tensorflow scikit-learn mysql-connector-python
import pandas as pd
from keras import Sequential
from keras.src.layers import Dense, SimpleRNN, Dropout, LSTM
from sklearn.preprocessing import MinMaxScaler
from G import G
shift=1
conn, cursor=G.connect()
cursor.execute("select * from 台灣股市 where 代號 = 'GC=F' order by 日期")
rs=cursor.fetchall()
columns=[d[0] for d in cursor.description]
df=pd.DataFrame(rs,columns=columns)
scaler = MinMaxScaler()
df["scaler"]=scaler.fit_transform(df[["收盤"]])
data=pd.DataFrame([df["scaler"].iloc[i:i+shift].tolist() for i in range (len(df)-shift+1)])
data["target"]=df["scaler"].shift(-shift)
data=data.dropna()
#混亂, 建議不要混亂
#data = data.sample(frac=1, random_state=42).reset_index(drop=True)
train_x=data.iloc[:,0:shift]
train_y=data.iloc[:,-1]
model=Sequential()
model.add(
LSTM(
units=128,
input_shape=(shift, 1),
)
)
model.add(Dropout(0.2))
model.add(Dense(1))
model.compile(
loss="mse",
optimizer="adam",
metrics=["mae"]
)
model.fit(
train_x, train_y,
# validation_data=(test_x, test_y)
batch_size=16,
epochs=200,
verbose=1,
)
model.save(f"gold_{shift}.keras")
預測
from datetime import timedelta
import keras
from sklearn.preprocessing import MinMaxScaler
import plotly.graph_objects as go
from G import G
import pandas as pd
shift=1
conn, cursor=G.connect()
cursor.execute("select * from 台灣股市 where 代號 = 'GC=F' order by 日期")
rs=cursor.fetchall()
columns=[d[0] for d in cursor.description]
df=pd.DataFrame(rs,columns=columns)
scaler = MinMaxScaler()
df["scaler"]=scaler.fit_transform(df[["收盤"]])
data=pd.DataFrame([df["scaler"].iloc[i-shift:i].tolist() for i in range (shift, len(df)+1)])
data["date"]=df["日期"].shift(-shift)
data["sale"]=df["收盤"].shift(-shift)
model=keras.models.load_model(f'gold_{shift}.keras')
gold=data.iloc[:,0:shift]
predict=model.predict(gold)
data["predict"]=scaler.inverse_transform(predict)
date=data.iloc[-2]["date"]
date=date+ timedelta(days=1)
data.iloc[-1, data.columns.get_loc("date")] = date
print(data)
period=-300
fig=go.Figure()
fig.add_trace(
go.Scatter(
x=data["date"][period:],
y=data["sale"][period:-1],
mode='lines',
name='實際價格',
line=dict(color='red', width=2)
)
)
fig.add_trace(
go.Scatter(
x=data["date"][period:],
y=data["predict"][period:],
mode='lines',
name='預測價格',
line=dict(color='green', width=2)
)
)
fig.update_layout(
dragmode="pan",
title_text="台灣黃金存摺歷史價格",
xaxis=go.layout.XAxis(
rangeselector=dict(
buttons=list([
dict(count=1,
label="1 month",
step="month",
stepmode="backward"),
dict(count=6,
label="6 month",
step="month",
stepmode="backward"),
dict(count=1,
label="1 year",
step="year",
stepmode="backward"),
dict(count=1,
label="1 day",
step="day",
stepmode="todate"),
dict(step="all")
])
),
rangeslider=dict(
visible=True
),
#range=[datetime.datetime(d.year, 1,1),datetime.datetime(d.year, d.month, d.day)],
type="date"
),
yaxis=dict(fixedrange=False)
)
fig.show()
FRED
黃金的漲跌跟 T10YIE 通膨預期有絕對關係。T10YIE 是10-Year Breakeven Inflation Rate 的縮寫,代表市場預期未來 10 年平均通膨率。黃金與 T10YIE 的相關性往往比 美國 CPI 指數(Consumer Price Index for All Urban Consumers,消費指數,CPIAUCSL) 的相關性更高
T10YIE 可由 FRED 美國官網下載,請進入如下網址註冊、登入,然後在 My Account 取得 api key
https://fred.stlouisfed.org/?utm_source=chatgpt.com
通膨下載代碥如下
import pandas as pd
from G import G
# display=pd.options.display
# display.max_columns=None
# display.max_rows=None
# display.width=None
# display.max_colwidth=None
url =f"https://api.stlouisfed.org/fred/series/observations?series_id=T10YIE&api_key={G.fred_api}&file_type=json"
# res = requests.get(url)
# data = res.json()
# df = pd.DataFrame(data["observations"])
# print(df)
data = pd.read_json(url)
df = pd.DataFrame(data["observations"].values.tolist())[["date", "value"]]
#將 . 轉成 Nan
df["value"] = pd.to_numeric(df["value"],errors="coerce")
df=df.dropna()
conn, cursor=G.connect()
cursor.execute("truncate table T10YIE")
cmd="insert into T10YIE (date, value) values (%s, %s)"
print(df.values.tolist())
cursor.executemany(cmd, df.values.tolist())
conn.commit()
conn.close()
todo