
Scrapy 是爬蟲的一個框架,其實也沒那麼偉大,它就是整合 requests 的 api 而以。
本篇的說明,只能使用在非前端動態網頁,也就是說資料不可以是 Ajax 所形成的。
以天降巨富這個小說而言,第一篇的網址是 http://www.uuxs.info/ls/22_22102/8233492.html,這是由後端所送出的,前端沒有任何 Ajax,所以適用本篇的說明。
安裝套件
請在 PyCharm 的 Terminal 執行如下指令
pip install Scrapy
建立專案
PyCharm 的 Terminal 執行如下指令
scrapy startproject novel
此時專案下會自動新增 novel 目錄。
之下又會有 novel/spiders 子目錄,
還有 items.py,settings.py 二個重要的檔案。
破除 robots 規範
網頁如果有設定 robots.txt 的話,Scrapy 會遵循裏面的規範,但有誰要去遵循啊,所以開啟 novel/novel/settings.py,將 ROBOTSTXT_OBEY 改成 False。
#ROBOTSTXT_OBEY = True ROBOTSTXT_OBEY = False
設定下載網址
在PyCharm 的 Terminal 下執行如下指令
cd novel
scrapy genspider itcast "uuxs.info/"
執行完 novel/novel/spiders/ 下會自動新增 itcast.py 檔,然後修改 itcast.py 成如下
import scrapy
class ItcaseSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["uuxs.info"]
start_urls = ["http://www.uuxs.info/ls/22_22102/8233492.html"]
def parse(self, response):
filename = "no1.html"
open(filename, 'wb+').write(response.body)
測試
上面代碼紅色的部份,只是為了測試用的。執行下面指令,就會開始爬取網頁,並將其 html 儲存在專案根目錄下的 no1.html 中,可以打開看到裏面的內容。若打開後沒任何東西,表示測試失敗。
scrapy crawl itcast
開始爬蟲
上述可以連線成功下載 html後, 就可以尋找 xpath 並列印。
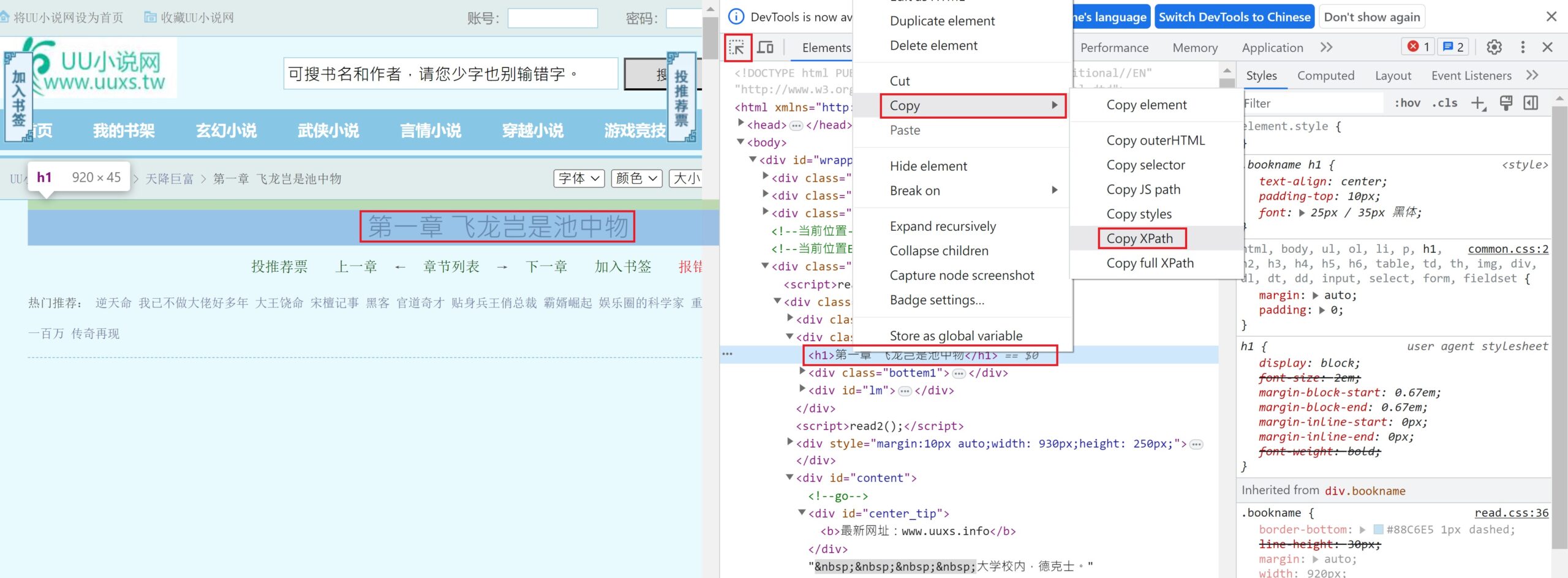
尋找XPAPH
在網頁按下 “F12″,然後依下圖 Copy XPath
修改 itcast.py執行
使用 response.xpath 查詢要爬取的資料,下面藍色的部份就是 F12 取得的 xpath,最後後 extract() 將資料萃取出來。
import scrapy
class ItcaseSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["uuxs.info"]
start_urls = ["http://www.uuxs.info/ls/22_22102/8233492.html"]
def parse(self, response):
# filename = "no1.html"
# open(filename, 'wb+').write(response.body)
title = response.xpath('//*[@id="wrapper"]/div[4]/div/div[2]/h1').extract()
context = response.xpath('//*[@id="content"]').extract()
print(title)
print(context)
執行
跟測試指令一樣
scrapy crawl itcast
結果:
2023-08-13 00:55:41 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://www.uuxs.info/robots.txt> (referer: None)
2023-08-13 00:55:41 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.uuxs.info/ls/22_22102/8233492.html> (referer: None)
['<div id="content"><!--go-->\r\n<div id="center_tip"><b>最新网址:www.uuxs.info</b></div>\xa0\xa0\xa0\xa0大学校内,德克士。<br>\n<br>\n\xa0\xa0\xa0\xa0一个漂亮的长发女生,正一边吃
着薯条,一边刷着手机,一边晃荡着白皙的长腿。<br>\n<br>\n\xa0\xa0\xa0\xa0面前堆着烤翅、汉堡
......
編入字典
https://www.runoob.com/w3cnote/scrapy-detail.html
心得
Scrapy 整合了 requests, BeautifulSoup4 的功能,最後只用 xpath 取得資料,算是蠻簡約利落的。